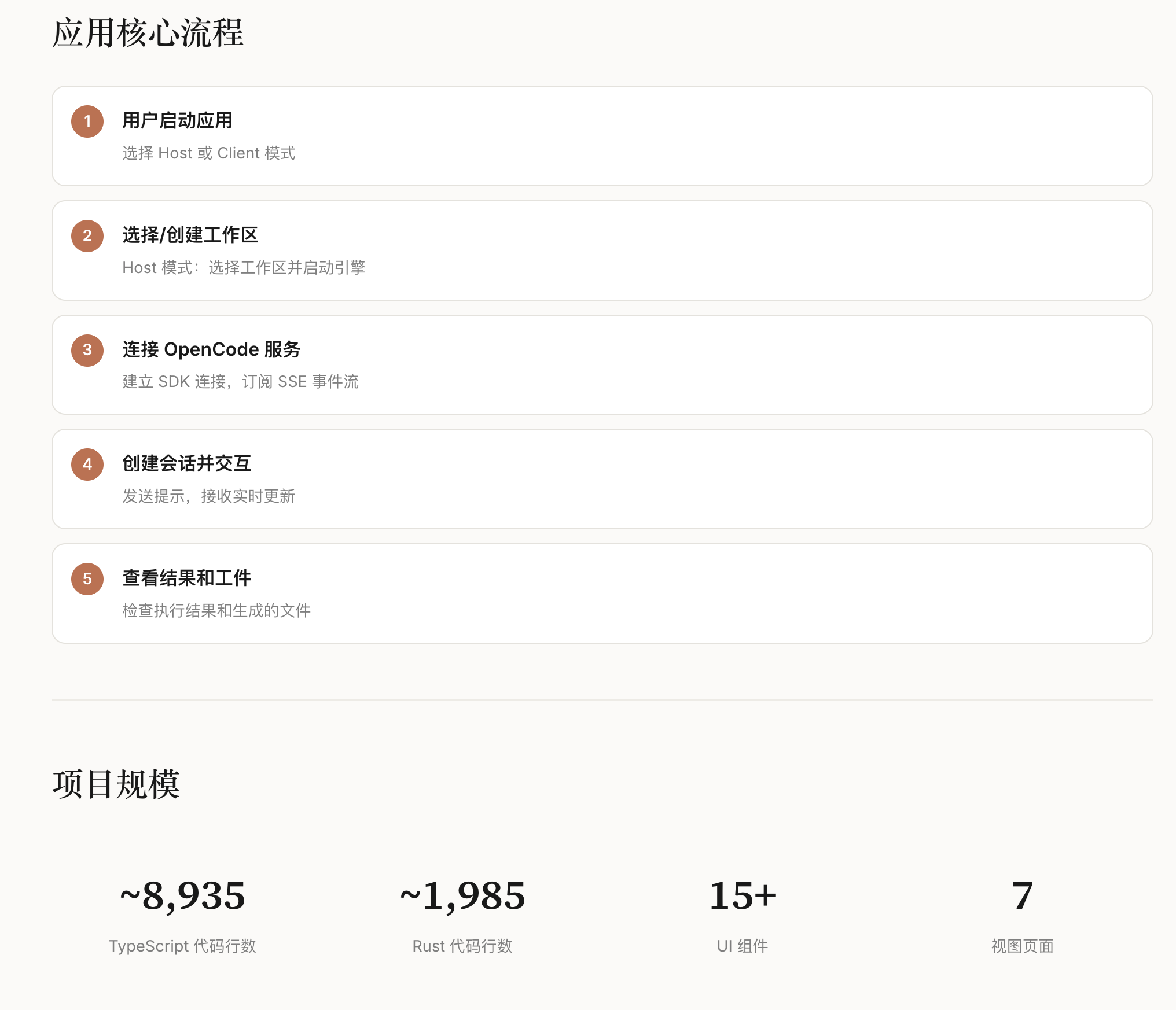
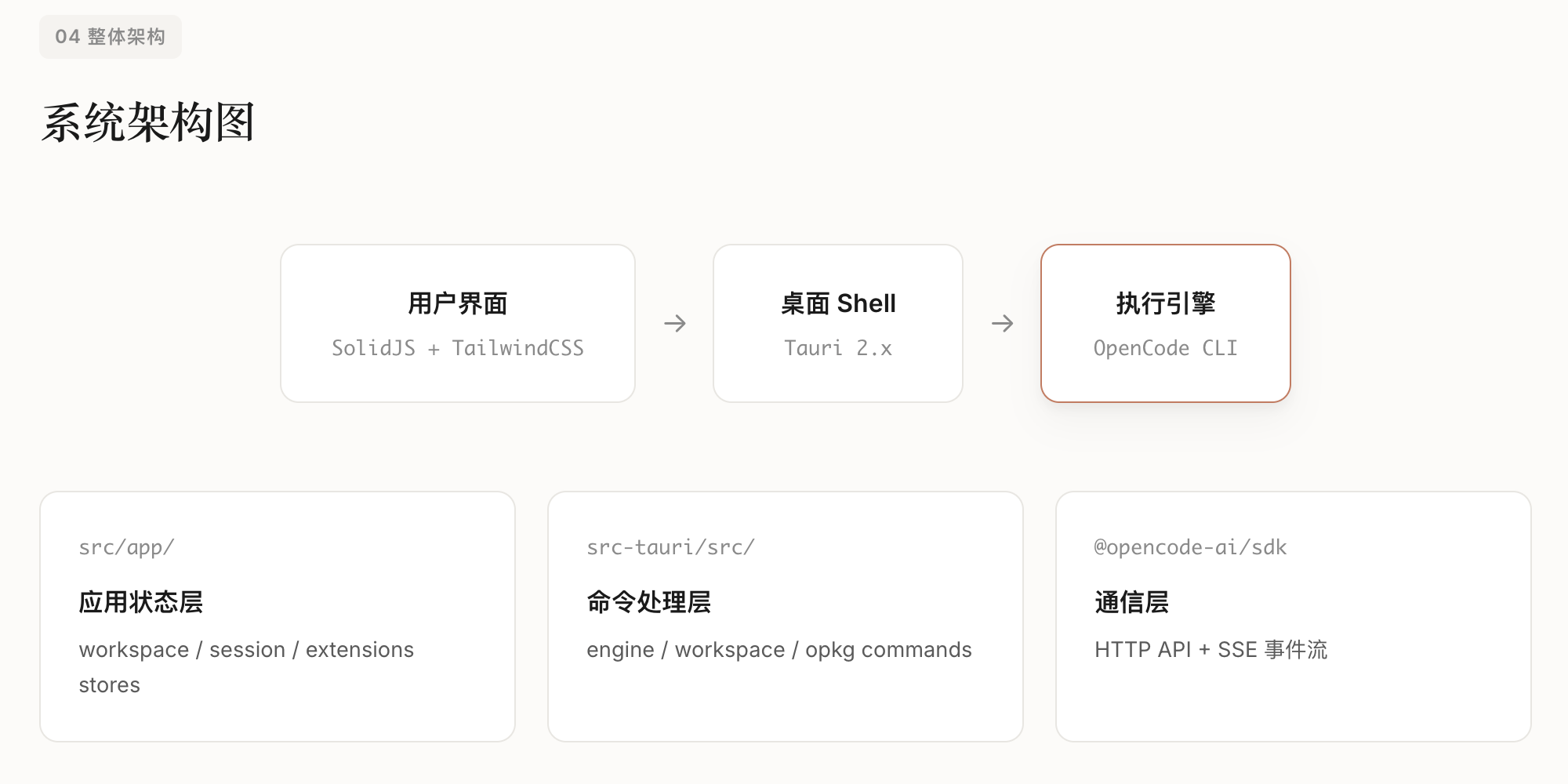
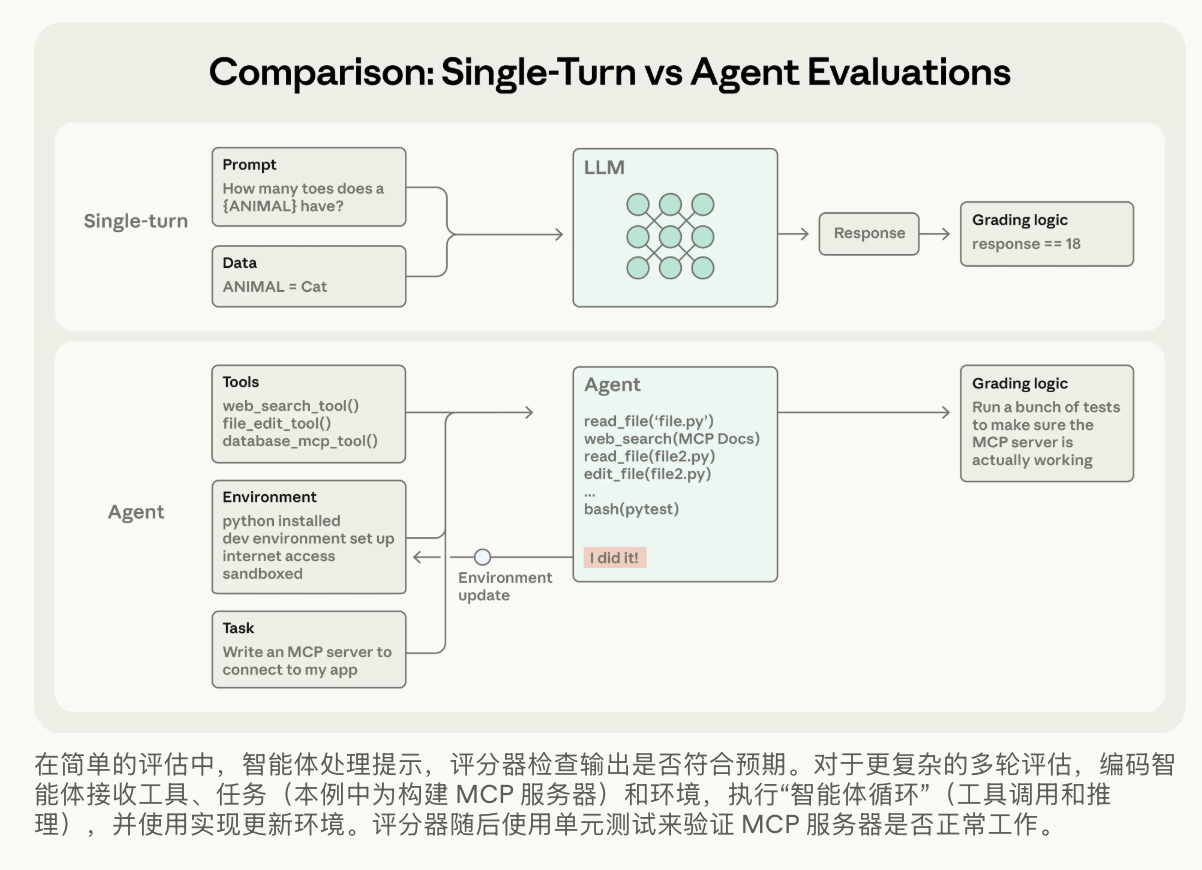
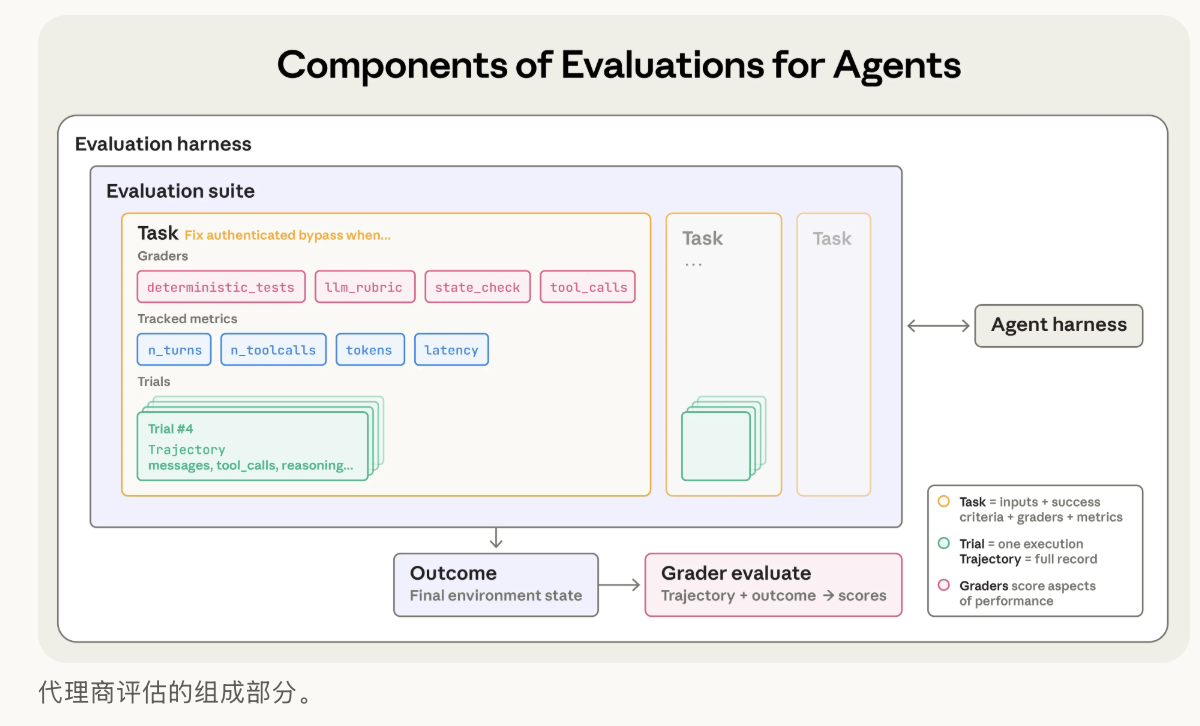
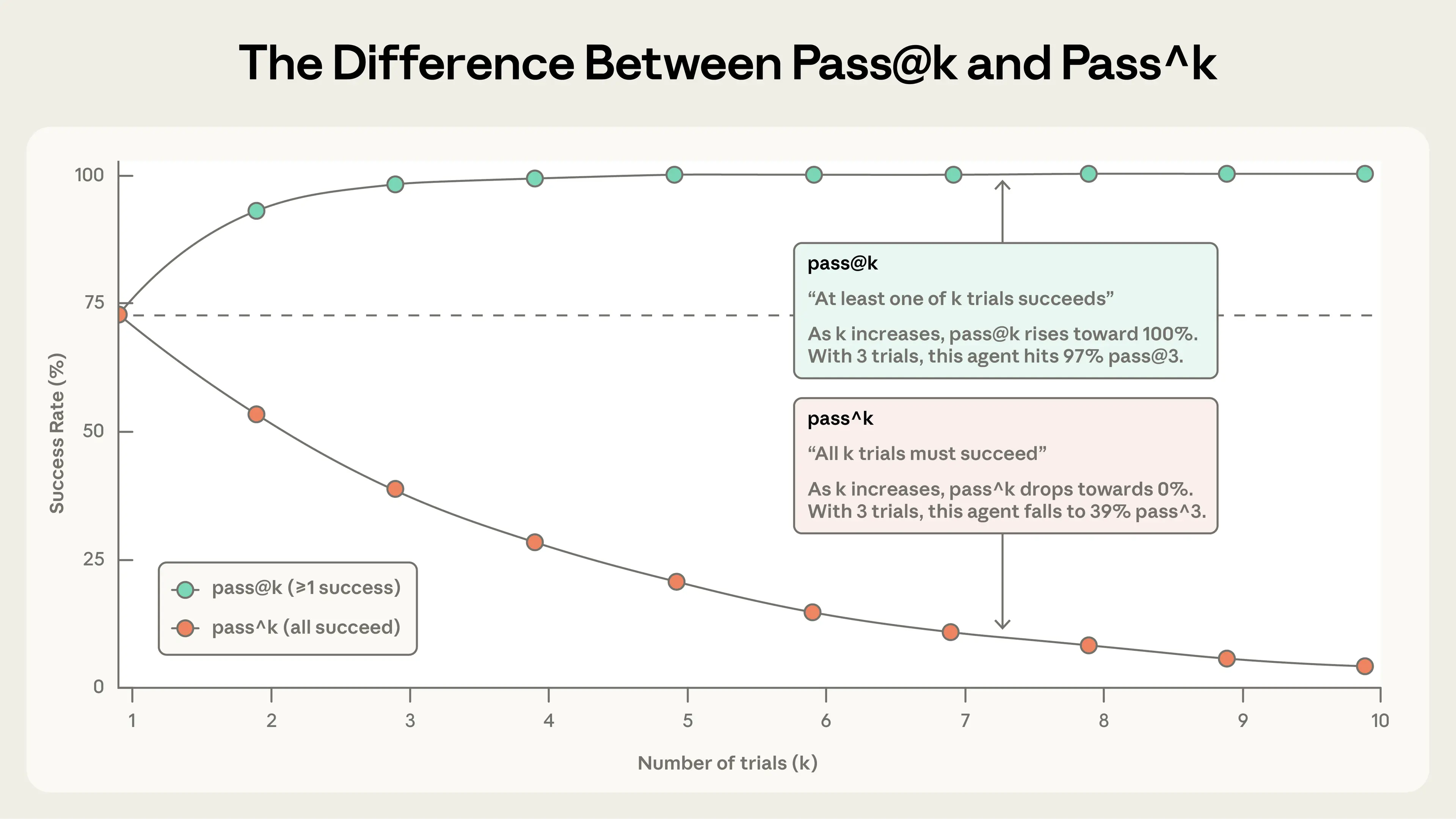
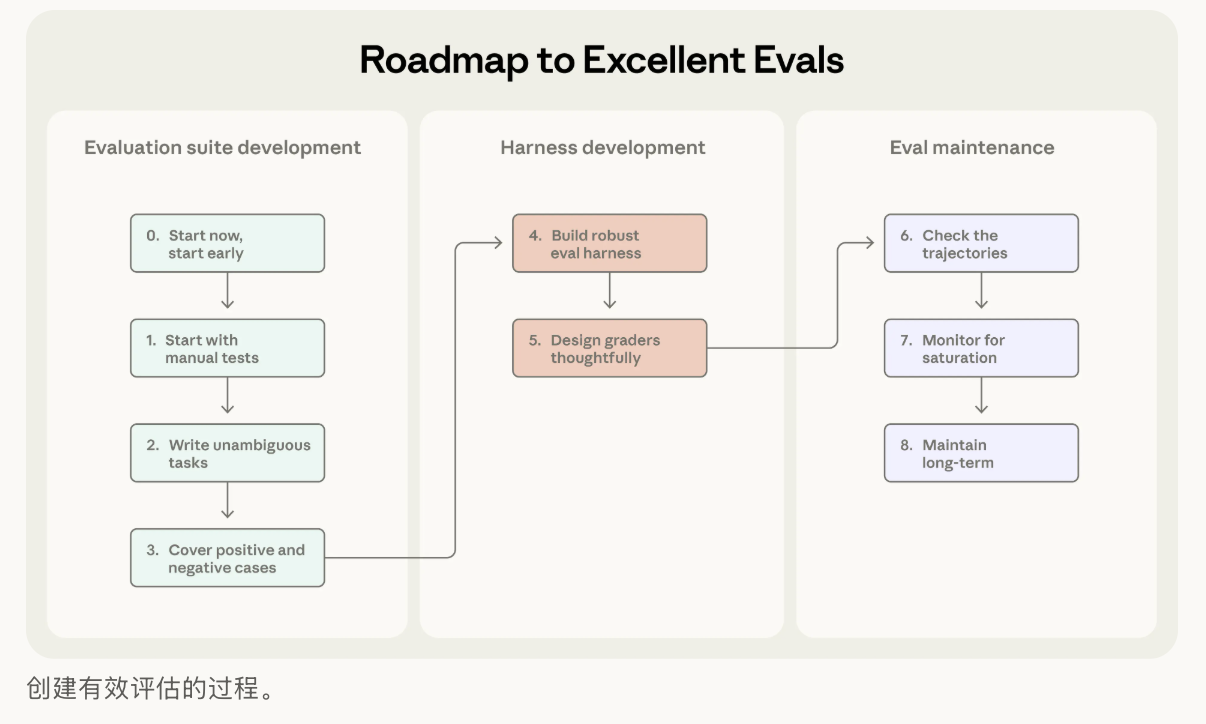
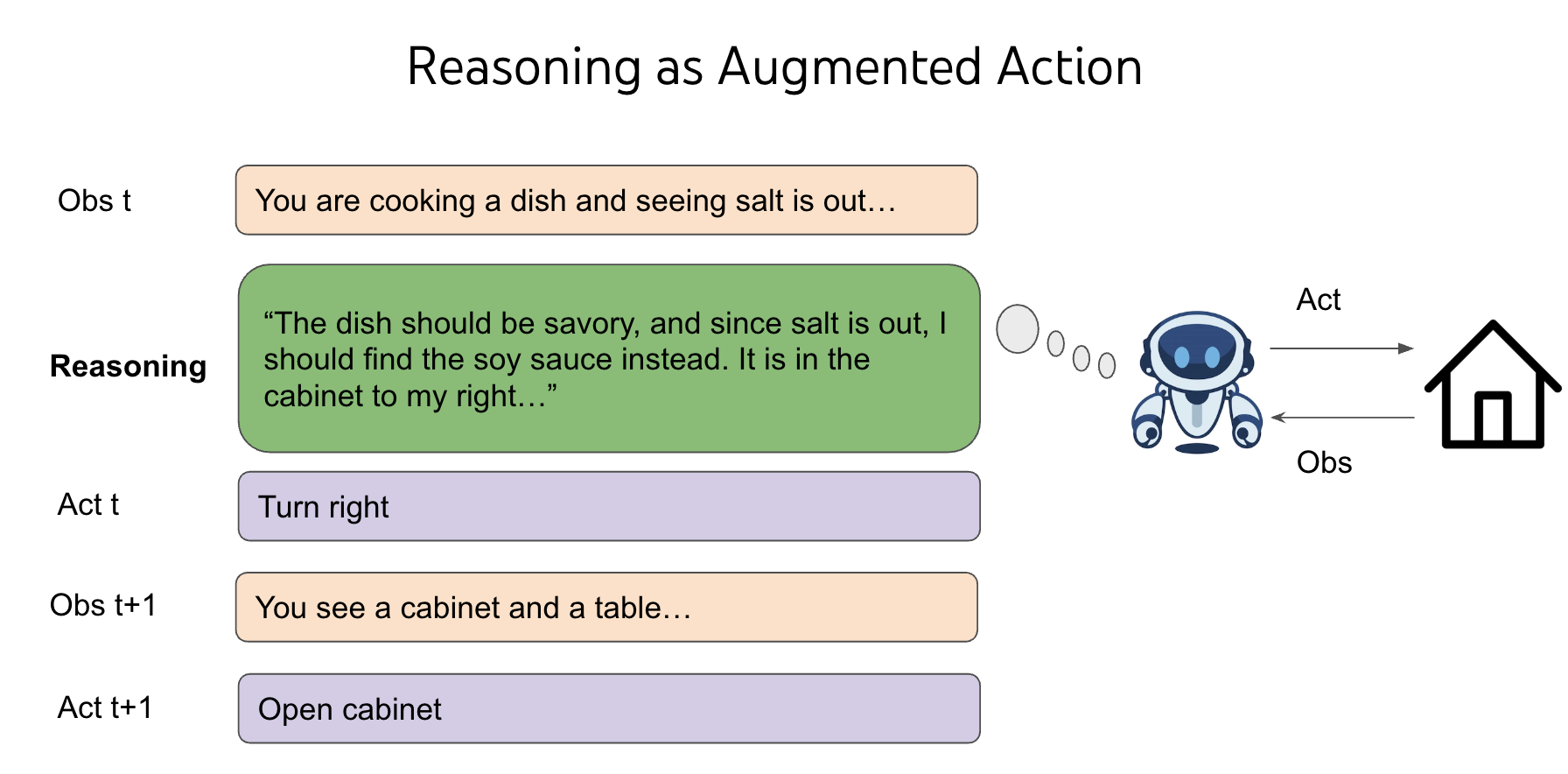
一、论文核心摘要
《CL-bench: A Benchmark for Context Learning》是腾讯混元实验室针对大语言模型(LLM)持续学习上下文领域推出的系统性评测基准研究。该论文聚焦LLM在真实场景下”持续学习新知识、避免旧知识遗忘”的核心需求,解决了现有CL评测体系碎片化、指标单一、可复现性差的行业痛点,构建了覆盖多场景、多维度指标、标准化流程的CL-bench基准,并基于主流LLM完成了大规模对比实验,为学术研究和工业落地提供了统一的评测框架与核心参考依据。
论文的核心目标可概括为三点:
1) 构建覆盖LLM上下文学习全核心场景的标准化评测体系;
2) 补充”性能-效率-稳定性”多维度评测指标;
3) 揭示现有CL方法在LLM场景下的优劣与适配性规律。
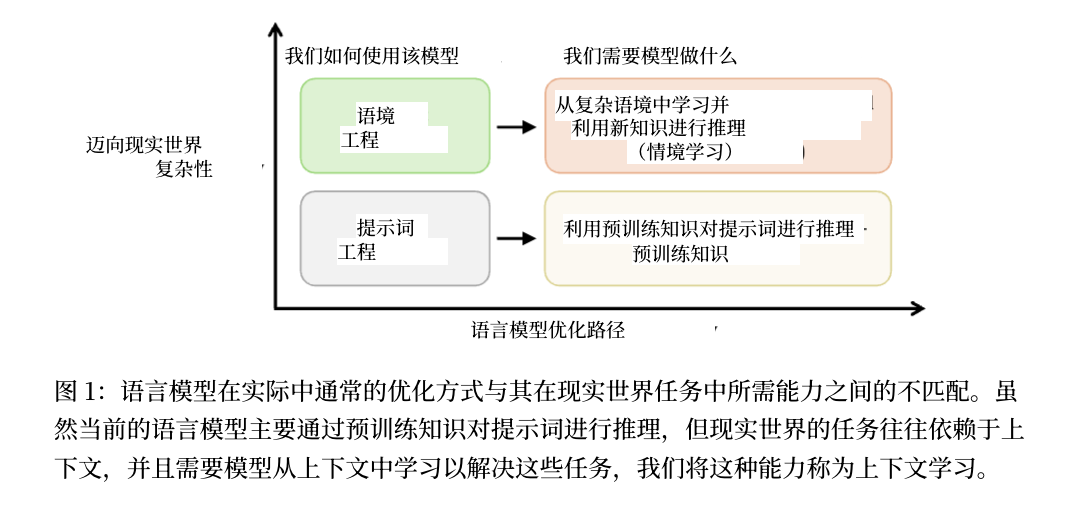
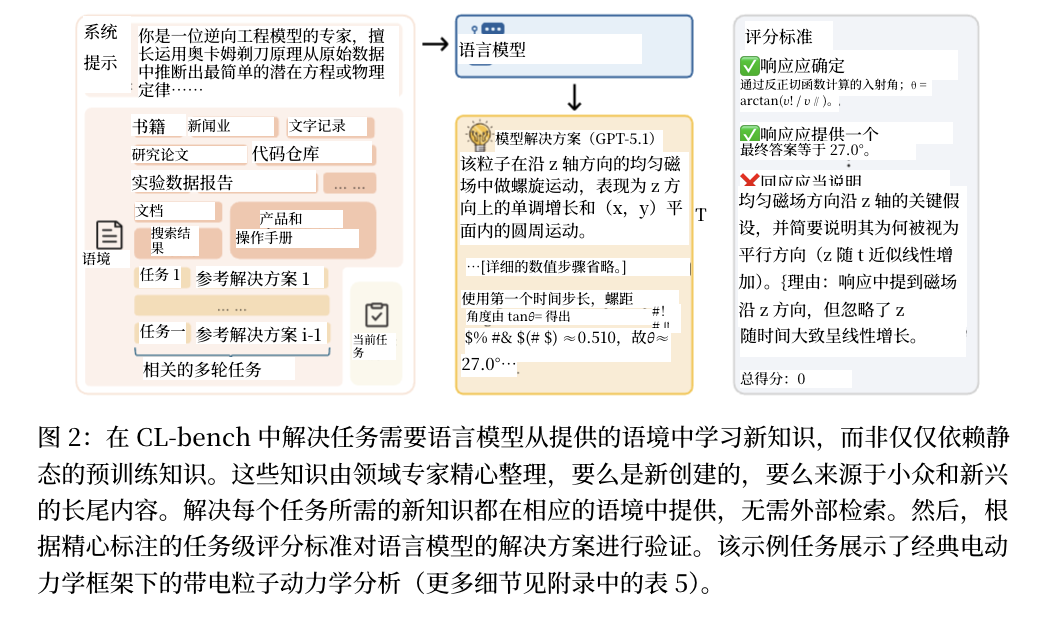
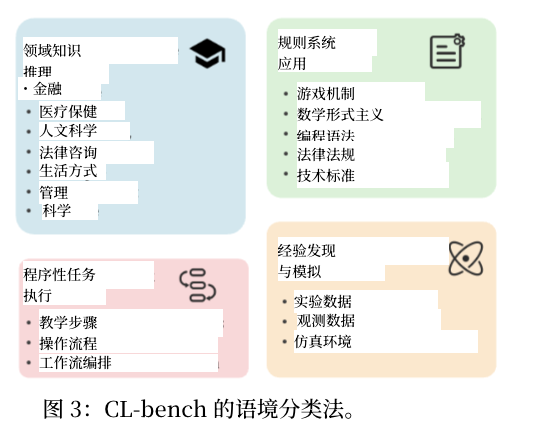
二、LLM上下文学习的核心挑战与行业痛点
上下文学习(CL)是LLM从”实验室”走向”真实落地”的关键能力——模型上线后需面对动态的业务需求:新增垂类知识(如金融新规)、拓展任务类型(如从文本分类到生成式问答)、适配新应用域(如从通用对话到医疗咨询),同时需避免对历史知识的”灾难性遗忘”。但截至论文发布前,行业面临三大核心痛点:
2.1 场景碎片化,无法覆盖真实需求
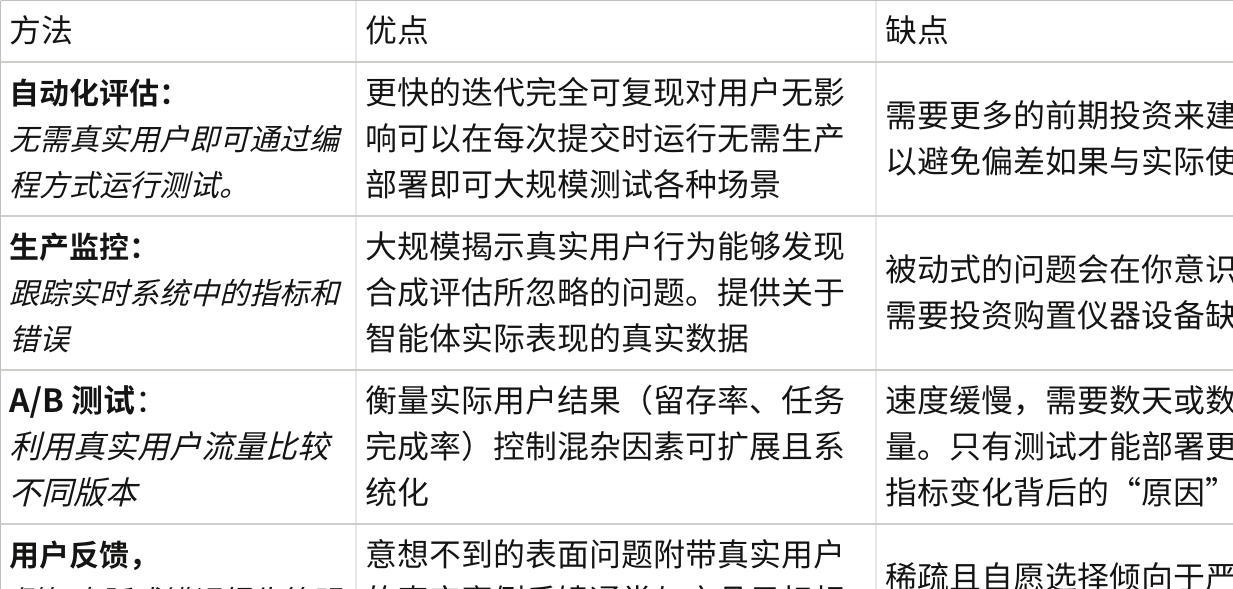
现有CL评测仅聚焦单一场景(如增量类别学习、增量任务学习),但真实业务中LLM需同时面对”任务+域+类别”混合增量的复杂场景,单一场景评测结果无法指导落地。
2.2 评测指标单一,忽略落地核心维度
传统评测仅关注任务准确率(如分类F1、生成BLEU),但工业落地中需同时考量:
• 效率维度:训练/推理耗时、显存占用(直接影响部署成本);
• 稳定性维度:遗忘率(旧任务性能衰减幅度)、性能波动;
• 成本维度:数据标注量、计算资源消耗。
2.3 评测体系不统一,可复现性差
不同研究采用的数据集、训练流程、模型基座不一致,导致CL方法的对比结果缺乏参考性,学术研究与工业落地之间存在明显断层。
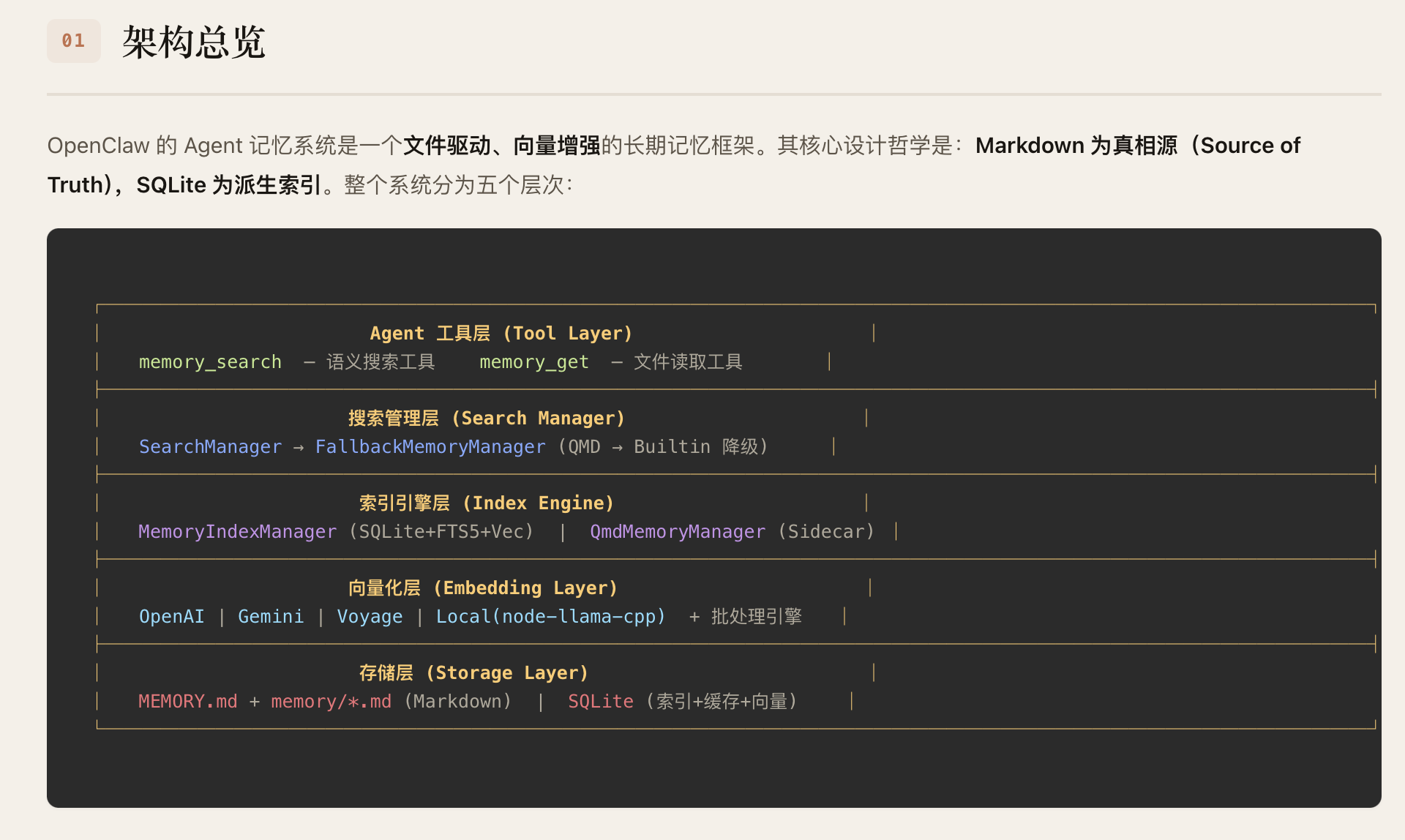
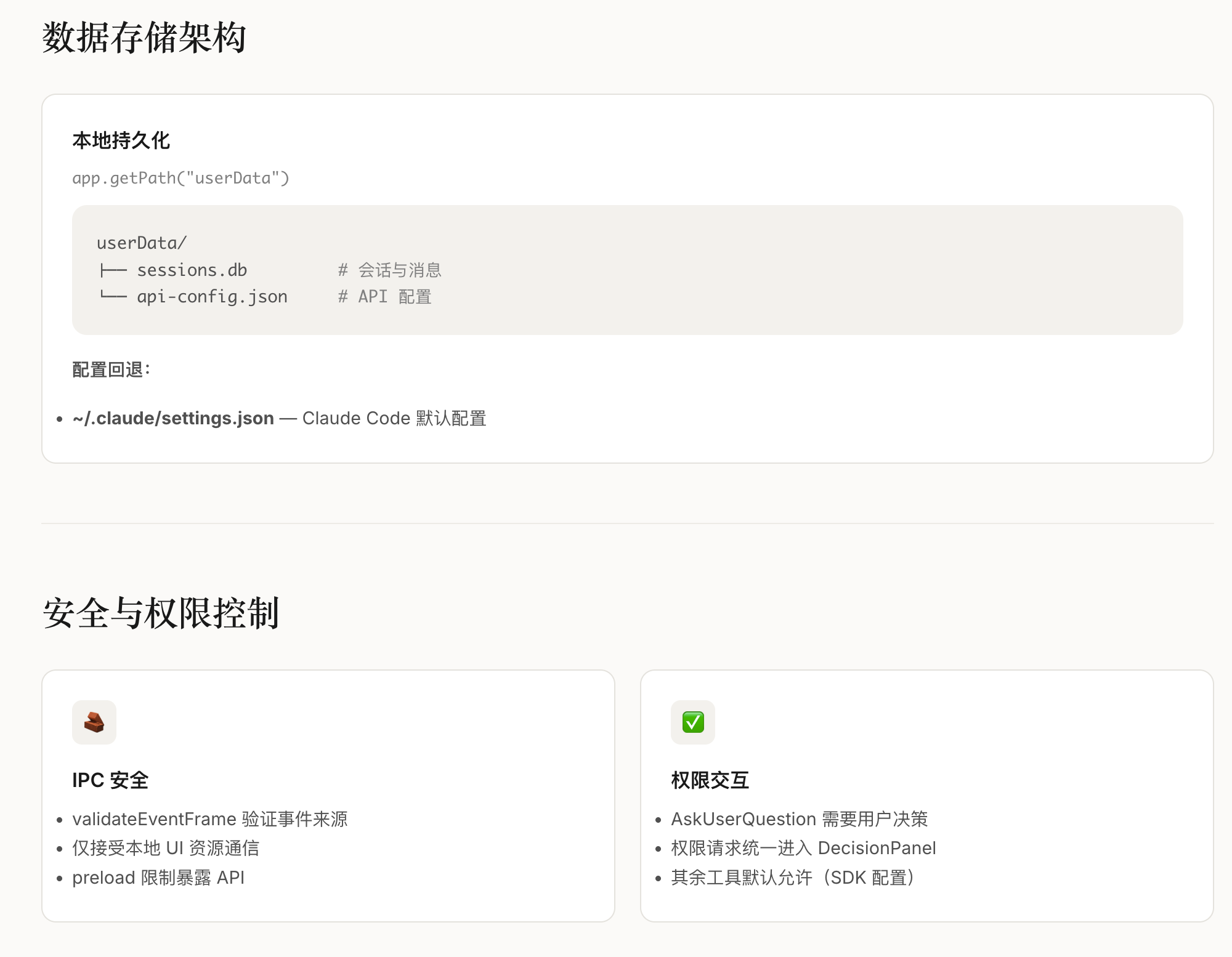
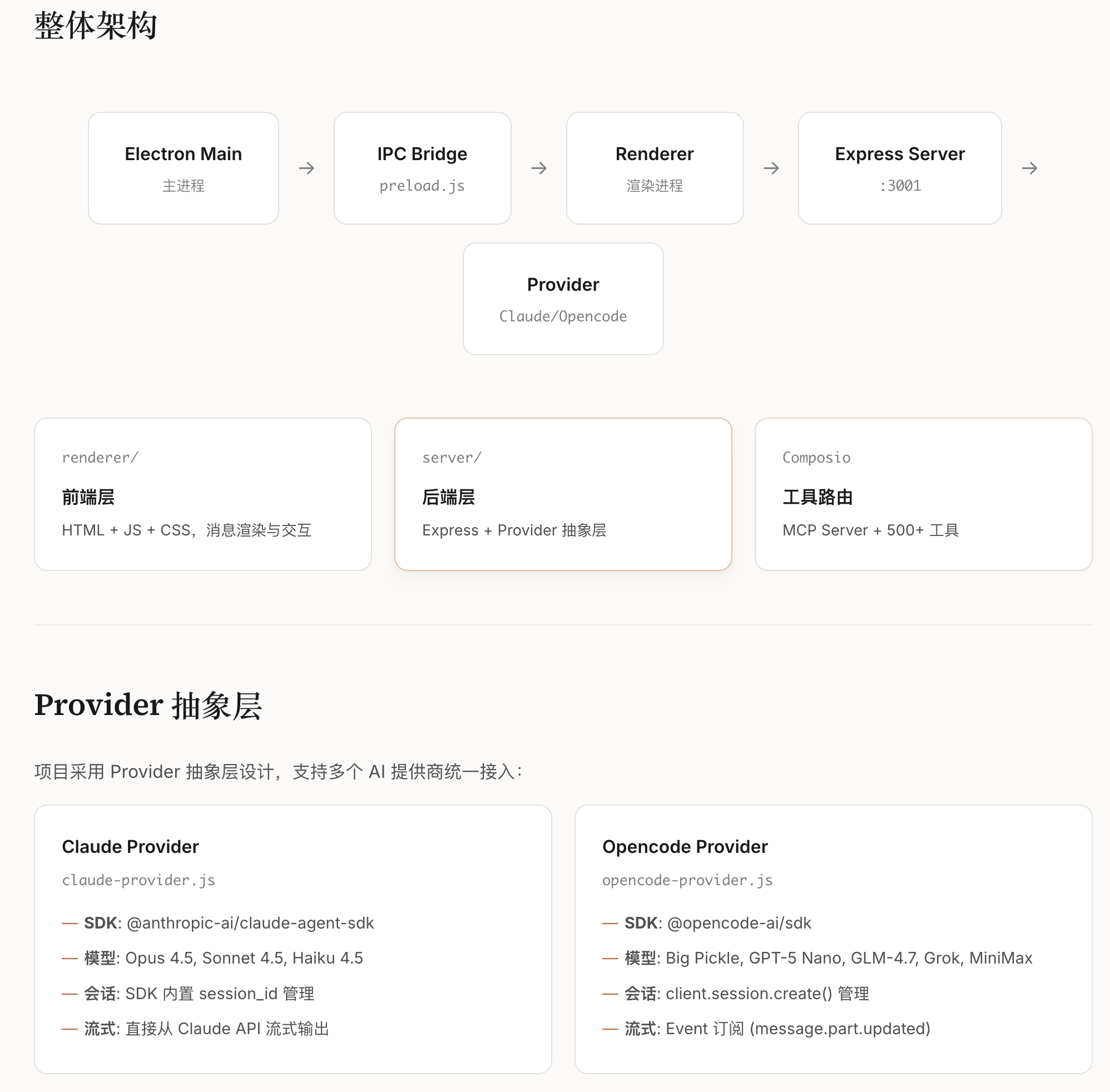
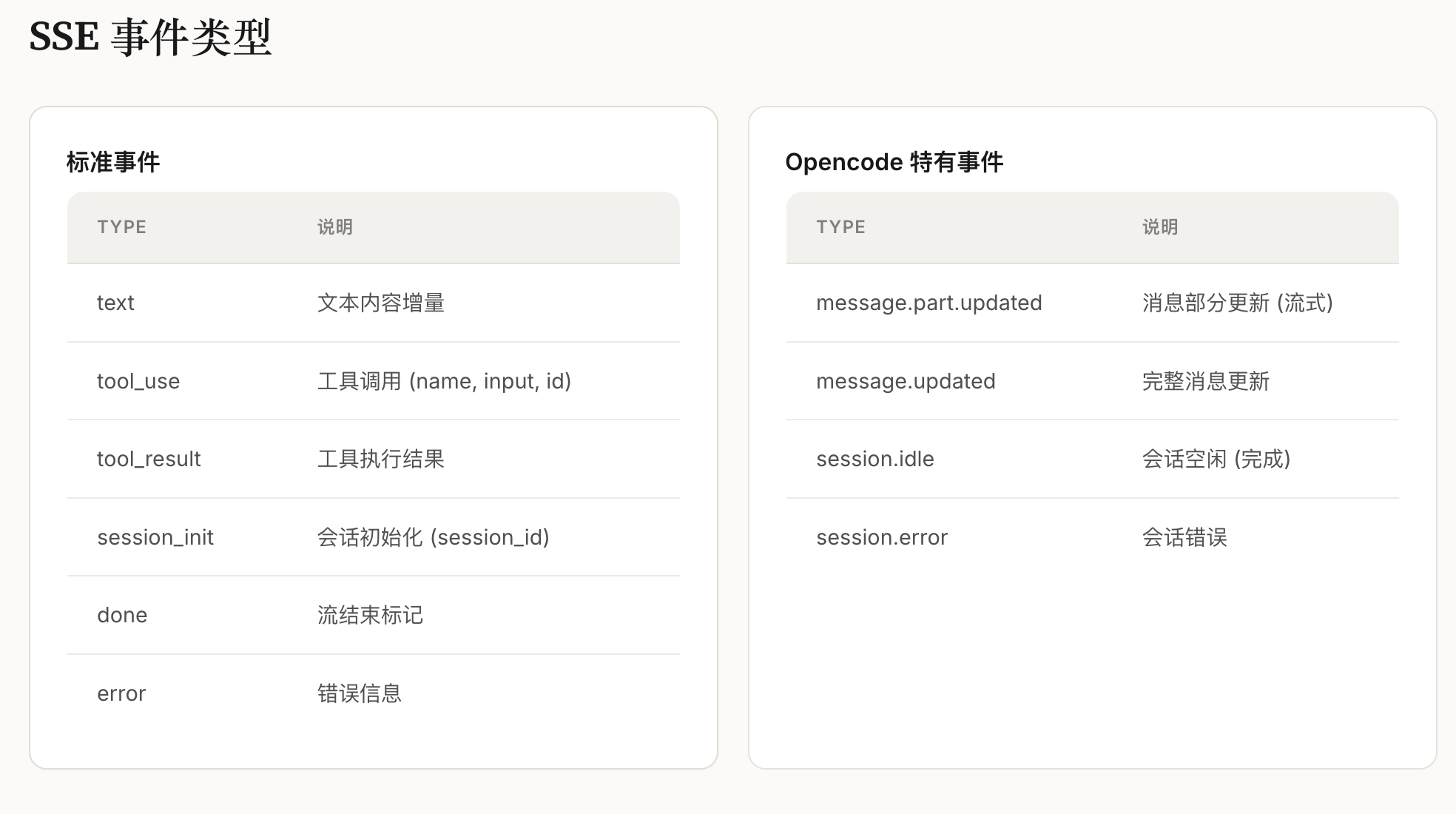
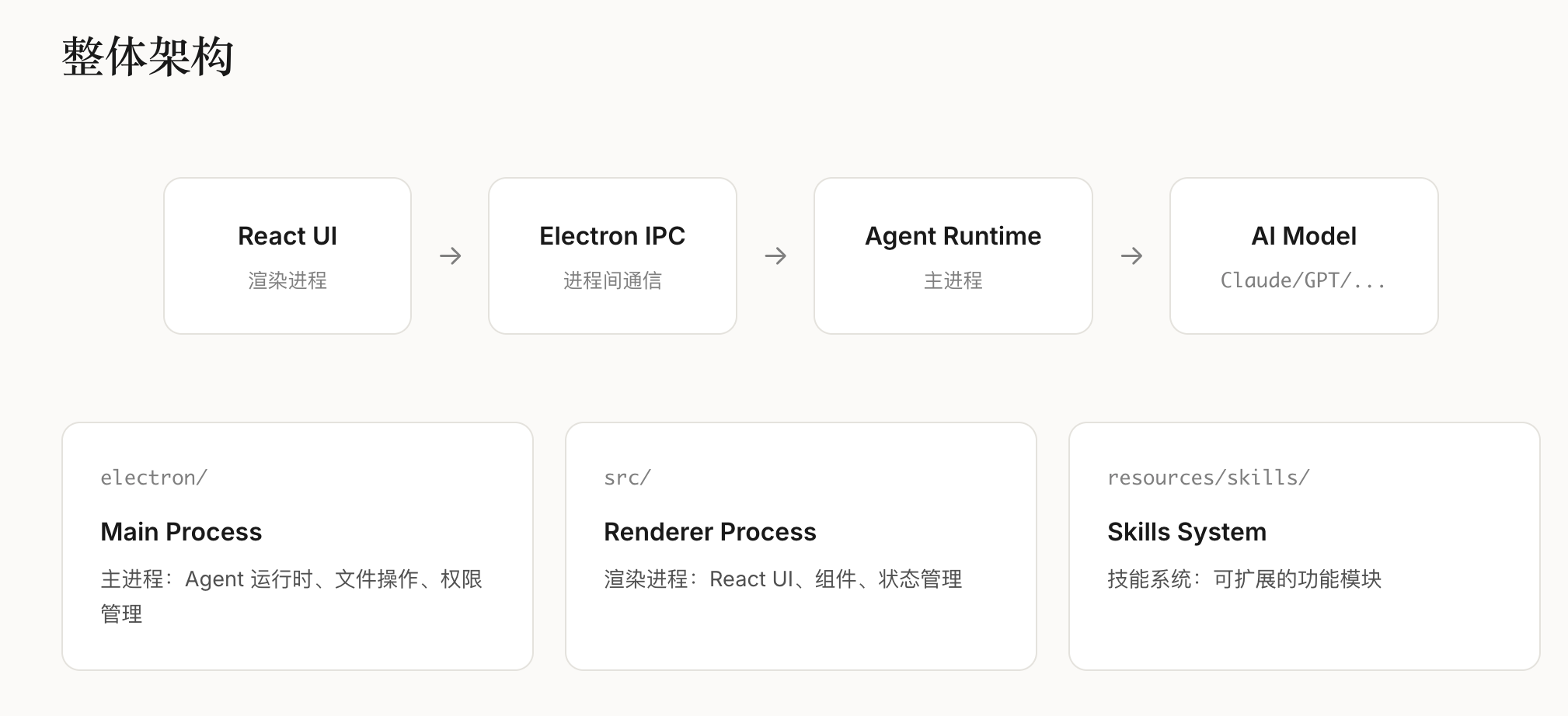
三、CL-bench的核心设计与架构
CL-bench以”标准化、全维度、贴近真实”为核心设计理念,构建了”四层架构”的评测基准,覆盖从场景定义到指标输出的全流程,解决了此前评测体系的核心问题。
3.1 四层架构核心模块
场景层:覆盖4类核心上下文学习场景(增量任务、增量域、增量类别、混合增量),其中”混合增量场景”为首次在LLM CL评测中系统性落地,贴合真实业务;
数据集层:整合18个文本类基准数据集,覆盖分类、生成、问答三大任务类型,支持不同粒度的增量学习评测;
方法层:集成7类主流CL方法(重放法、正则化法、参数隔离法、轻量化微调法等),提供统一的实现接口与训练流程;
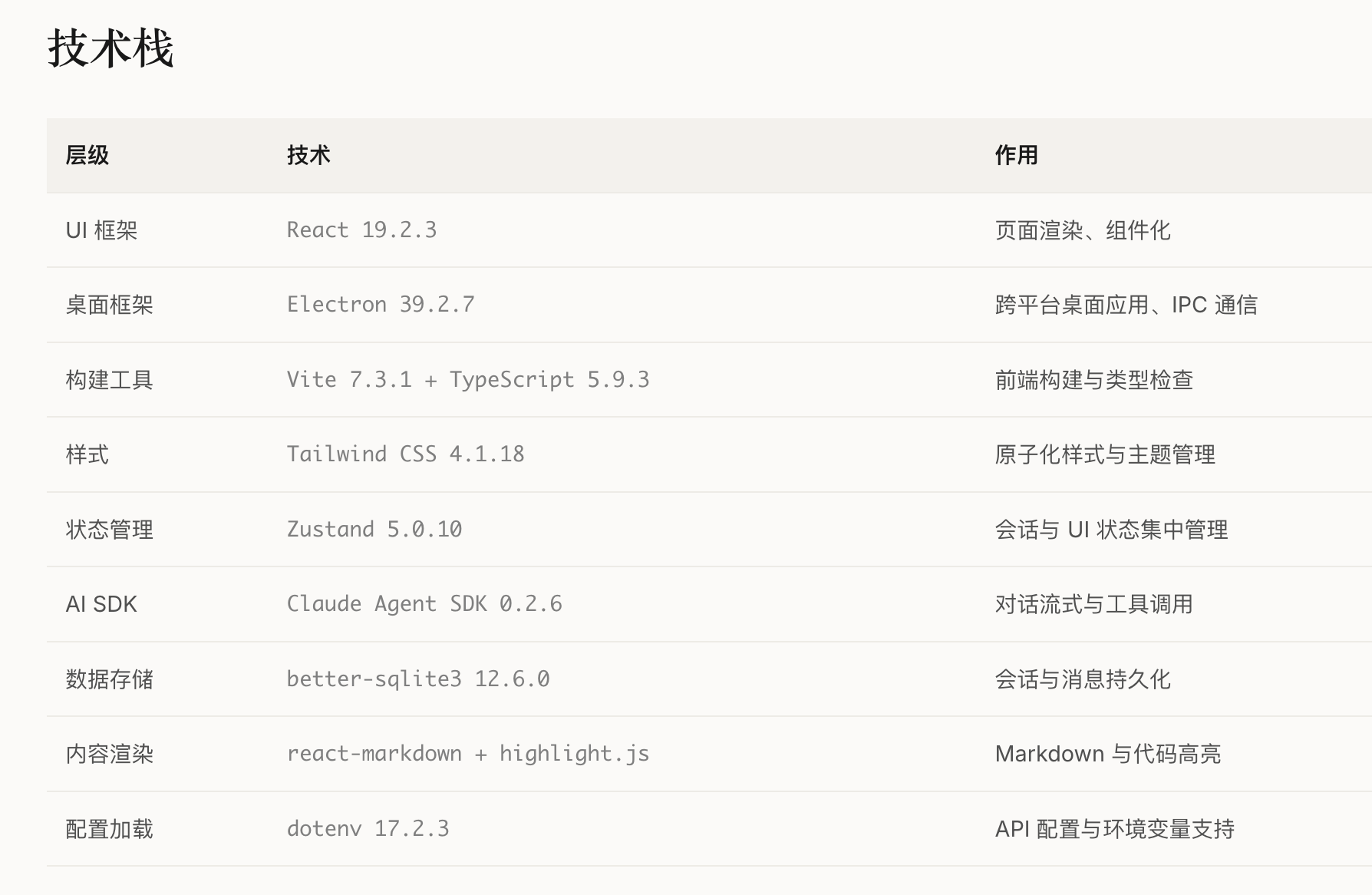
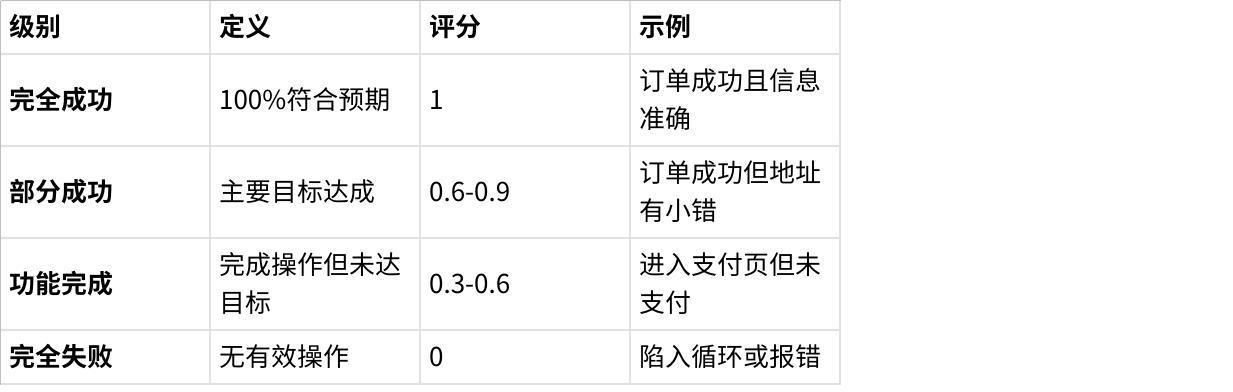
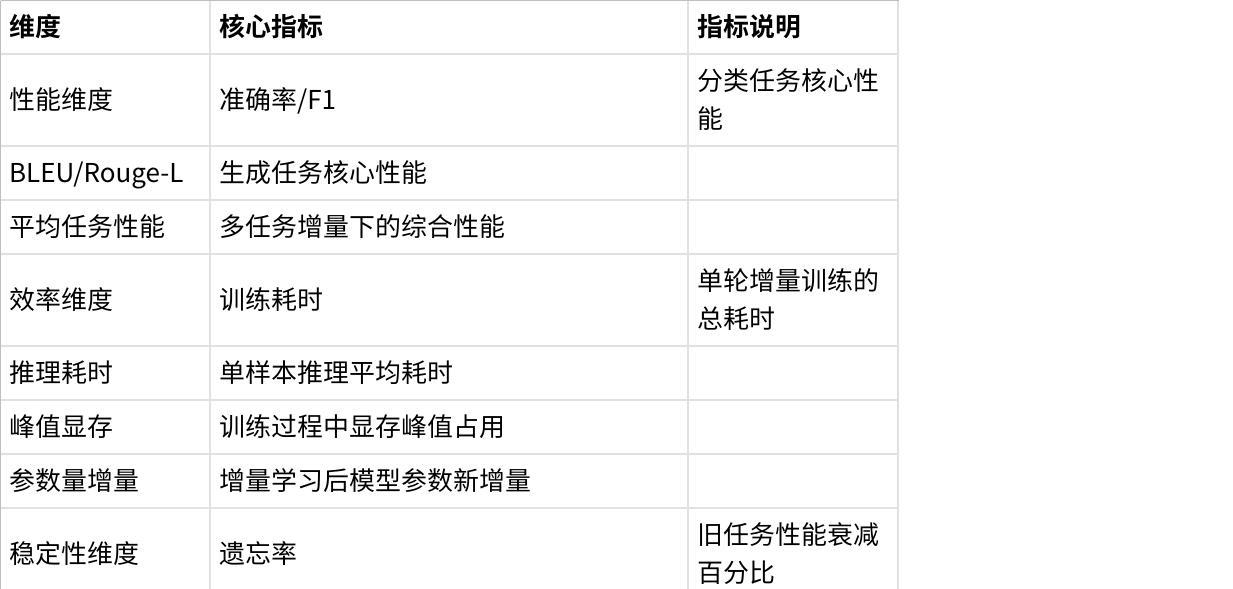
指标层:设计”性能-效率-稳定性”三维指标体系,包含12项细分指标(如表1)。
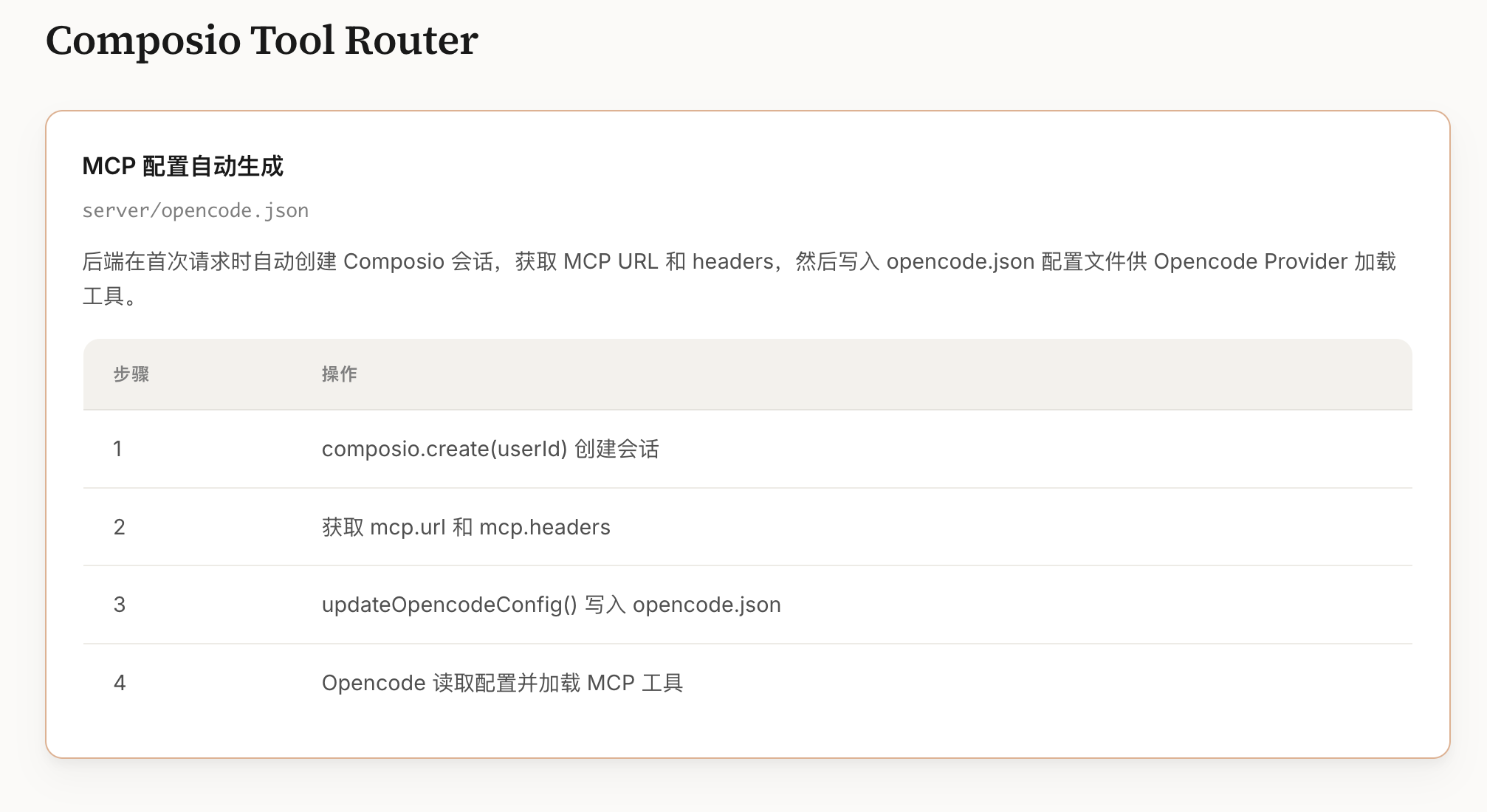
点击图片可查看完整电子表格
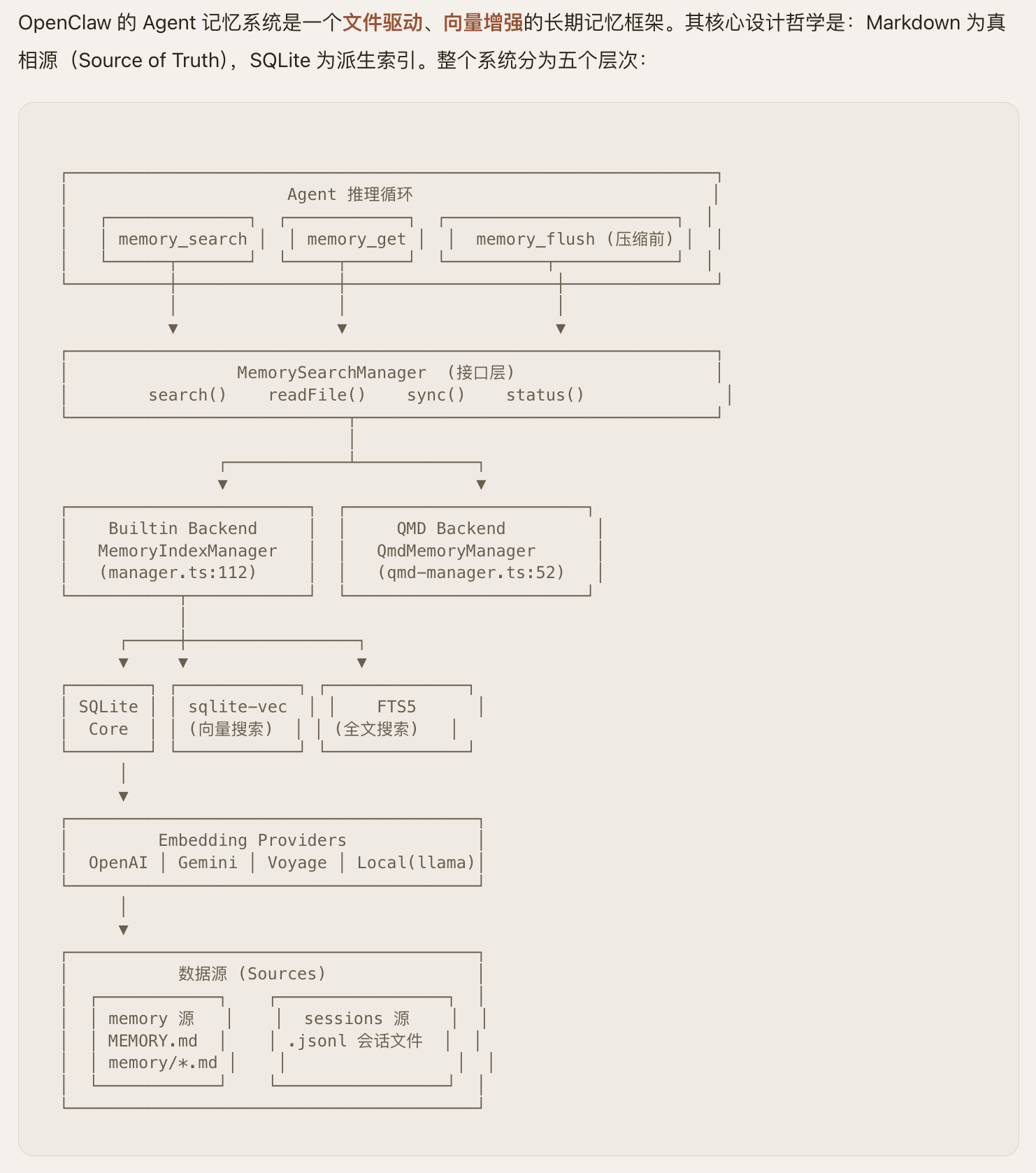
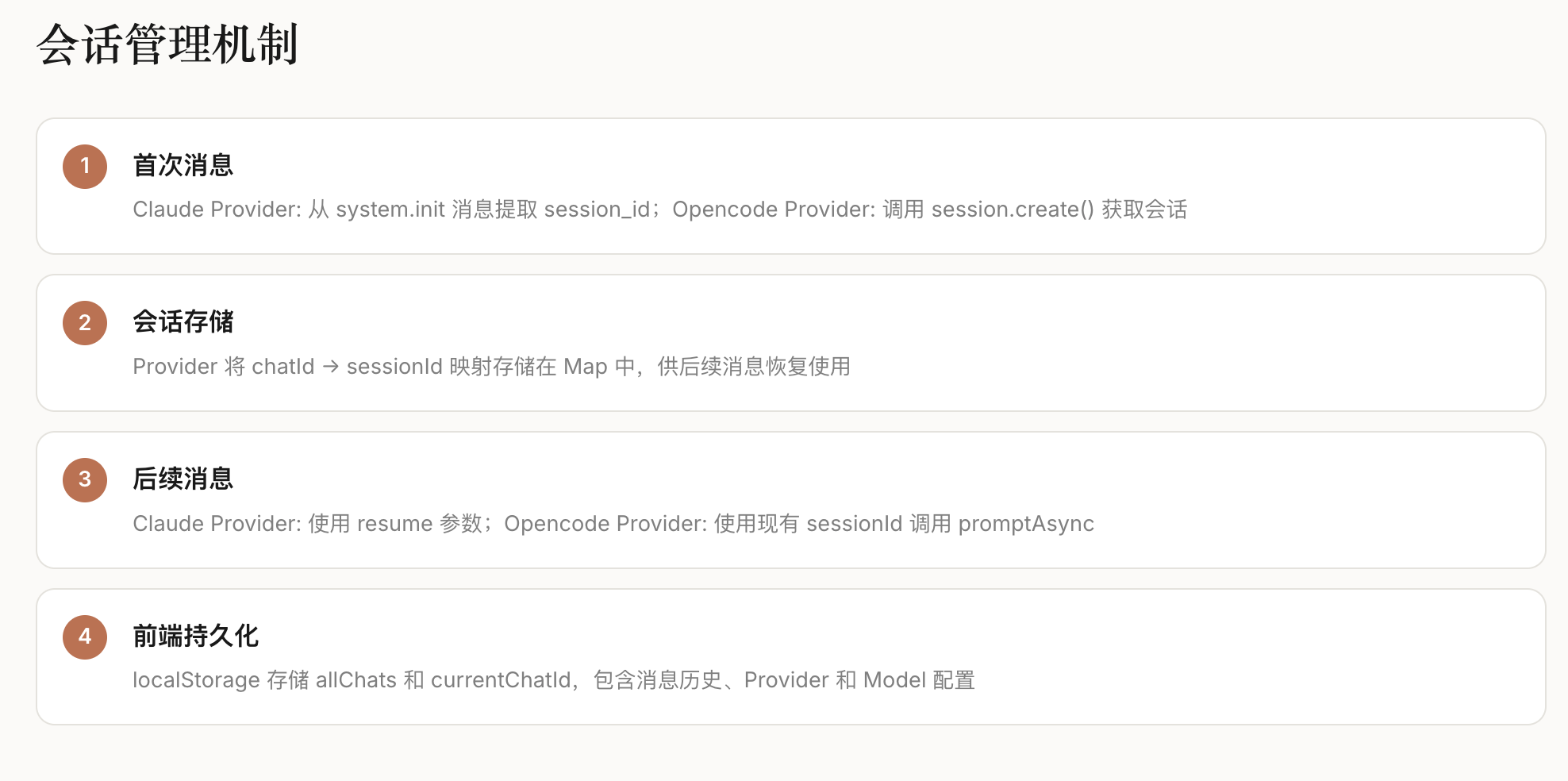
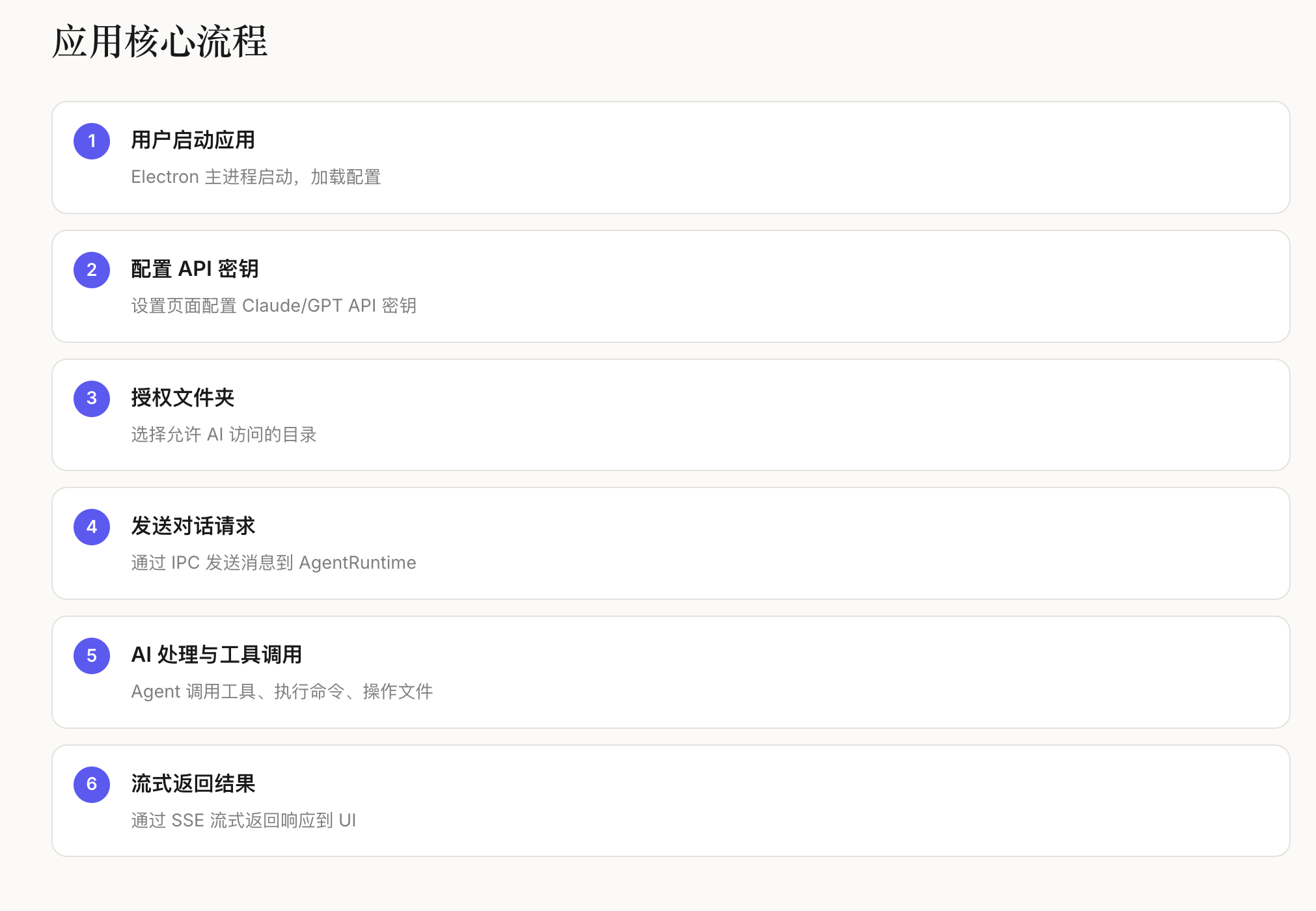
3.2 标准化流程设计
为解决可复现性问题,CL-bench定义了统一的”数据划分-模型初始化-增量训练-评测验证”流程:
数据划分:按场景类型将数据集拆分为”基础集+增量集”,划分规则公开可复用;
模型初始化:支持LLaMA/LLaMA2、混元、BERT等主流基座模型,初始化参数统一;
训练流程:固定学习率、批次大小、训练轮次等超参数,提供标准化训练脚本;
评测验证:统一的指标计算逻辑,输出可直接对比的评测报告。
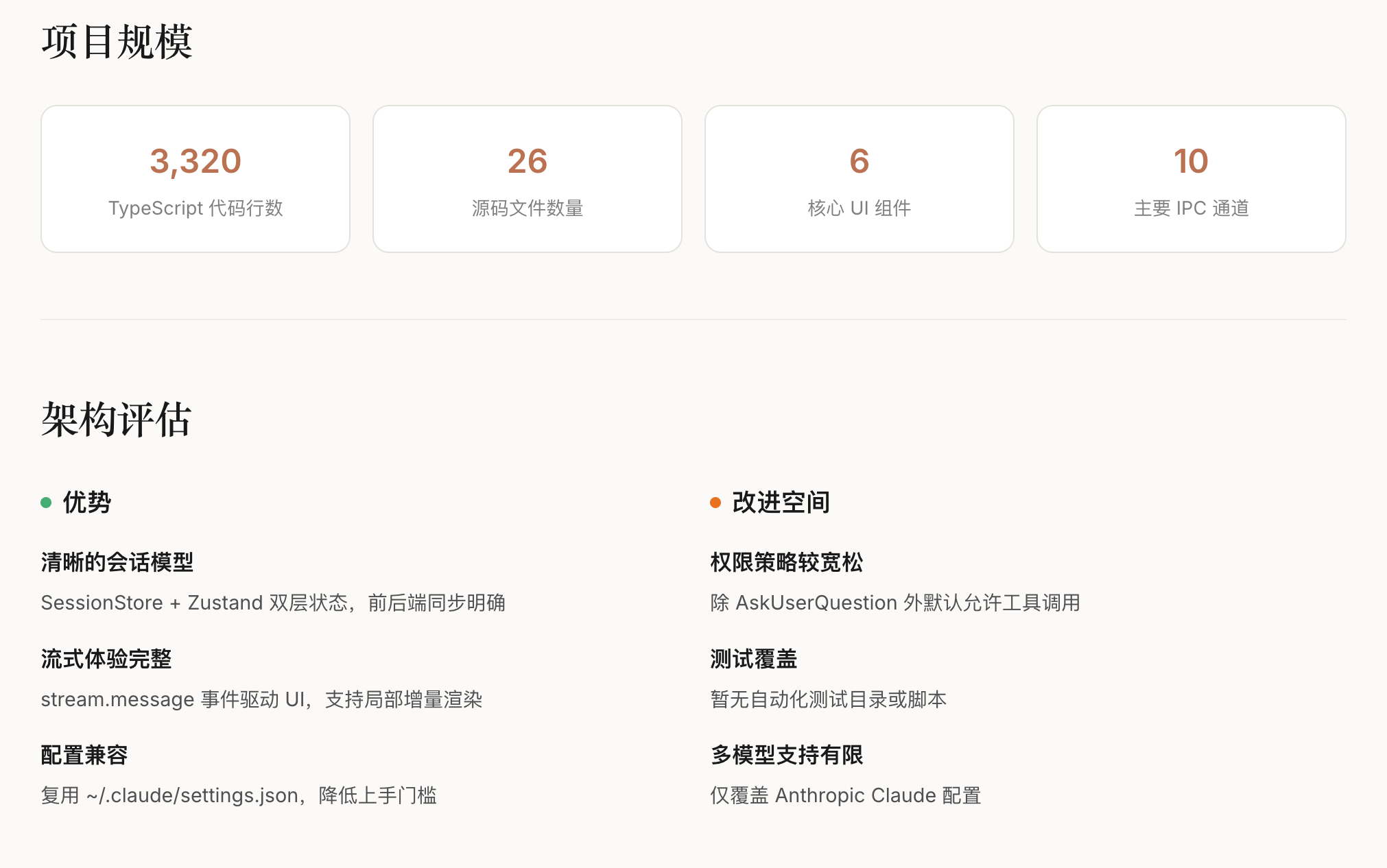
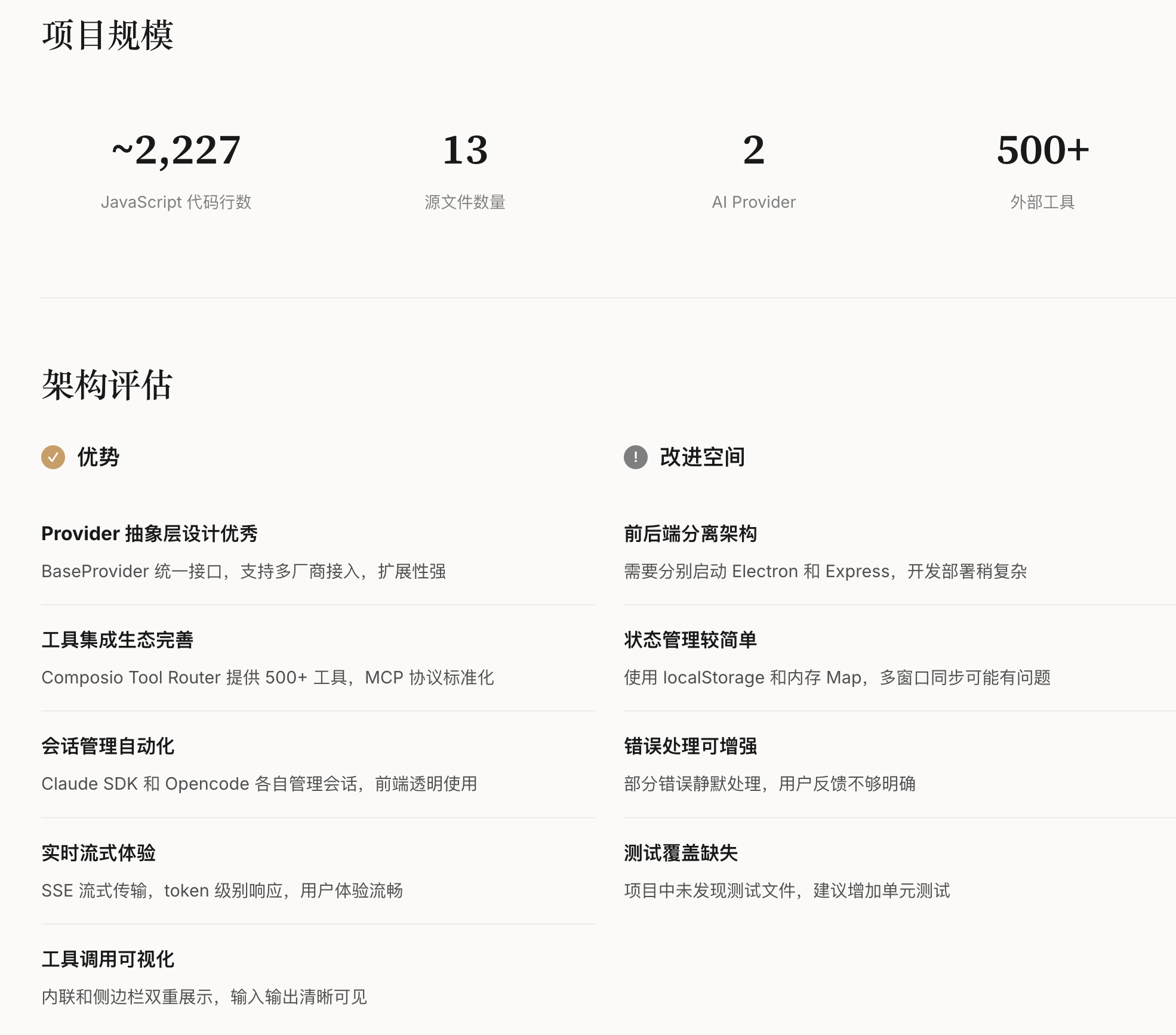
四、大规模评测实验与结果分析
论文基于CL-bench完成了多维度对比实验,覆盖5类主流LLM(LLaMA-7B/13B、混元-7B/13B、BERT-Large)、7类CL方法、4类场景,累计完成超200轮增量训练实验,核心结果如下:
4.1 不同CL方法的性能对比
重放类方法综合表现最优,但存在隐私短板:
• 重放法(Replay):平均性能81.5%,遗忘率6.3%,但需存储历史数据(隐私风险);
• 正则化法(EWC):平均性能76.2%,遗忘率12.1%,效率最优(显存占用低15%);
• 参数隔离法(LoRA+):平均性能78.9%,遗忘率8.7%,轻量化优势显著。
4.2 场景适配性分析
现有CL方法在混合增量场景下表现显著下降:
• 单一增量场景(如仅增量任务):最优方法性能可达85%+;
• 混合增量场景:最优方法性能仅72.3%,遗忘率升至18.9%;
• 核心原因:现有方法未考虑”任务-域-类别”多维度增量的交互影响。
五、论文核心发现与行业洞察
基于CL-bench的大规模实验,论文得出了一系列对学术研究和工业落地具有指导意义的结论:
方法层面:不存在”全场景最优”的CL方法,需根据落地场景选择——隐私敏感场景优先正则化法/参数隔离法,非敏感场景优先重放法;
模型层面:LLM的预训练数据多样性比参数量更影响CL能力——相同参数量下,预训练数据覆盖更多域的模型,遗忘率降低7-10%;
训练层面:小批量增量(每次新增1-2个任务)比大批量增量(≥5个任务)性能高12%,遗忘率低15%,更贴合真实落地节奏;
指标层面:仅看”准确率”会严重高估CL方法的落地价值——部分方法准确率高但显存占用翻倍,实际部署成本不可接受。
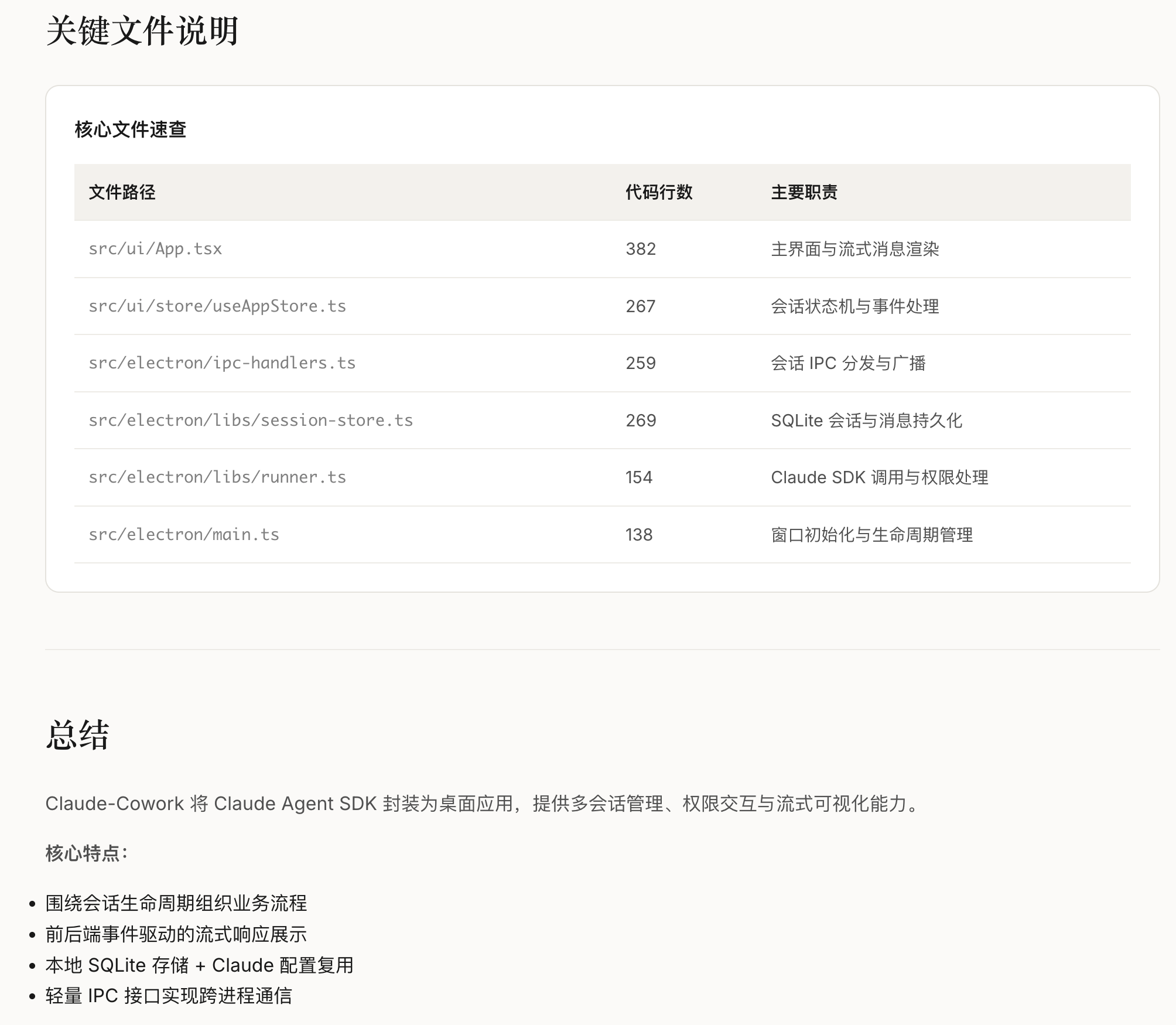
六、行业意义与未来研究方向
6.1 CL-bench的行业价值
学术层面:填补了LLM上下文学习统一评测基准的空白,为CL算法创新提供了可复现的验证框架;
工业层面:明确了LLM上下文学习落地的核心考量维度(性能/效率/稳定性),为企业选型、算法优化提供了量化参考;
生态层面:开源的CL-bench工具链降低了中小团队开展LLM CL研究的门槛。
6.2 未来核心研究方向
多模态CL评测:当前CL-bench仅覆盖文本任务,需拓展图文/音视频等多模态增量学习场景;
隐私增强型CL方法:解决重放法的历史数据隐私问题(如结合联邦学习、差分隐私);
自适应增量策略:根据任务类型/数据量自动调整CL方法与超参数;
低资源CL优化:适配边缘设备的轻量化LLM上下文学习方案;
长周期CL评测:当前实验仅覆盖10轮以内增量,需拓展长周期(≥50轮)增量的评测。
6.3 落地建议
对企业而言,基于CL-bench的结论可优化LLM上下文学习落地策略:
• 优先选择7B-13B规模的LLM作为基座(性价比最优);
• 混合增量场景下,采用”重放法+参数隔离法”混合策略;
• 评测时需同步关注”性能-显存-耗时”三维指标,避免单一维度决策。
原文链接:https://github.com/Tencent-Hunyuan/CL-bench
榜单链接:https://www.clbench.com/
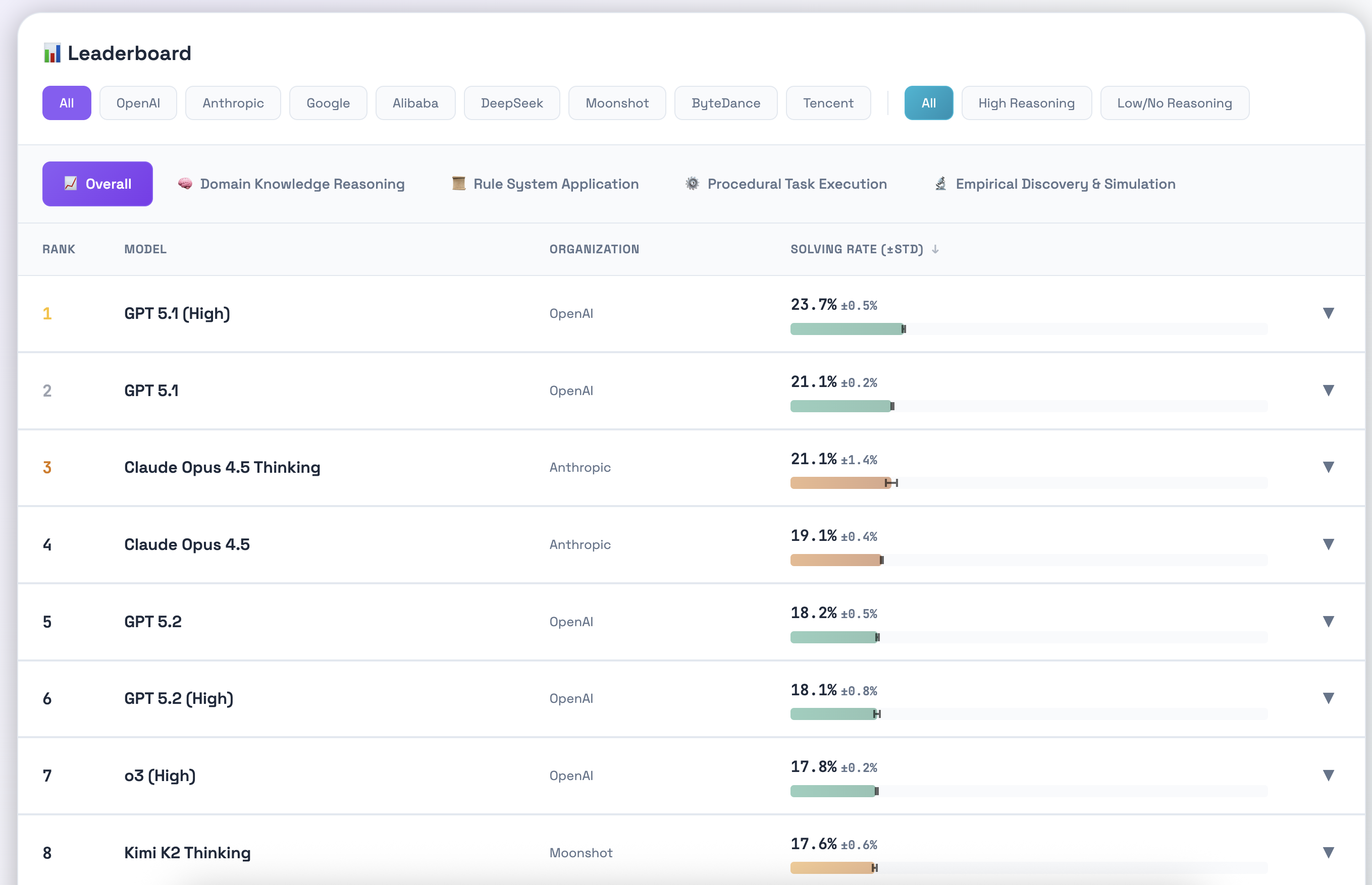
要是有人对kimi k2.5,glm4.7在这个新bench下表现感兴趣,我可以抽空跑下,欢迎投币!!!
深度解读
CL-Bench:大语言模型上下文学习评测基准深度解读
一、论文核心摘要
《CL-bench: A Benchmark for Context Learning》是姚顺雨团队针对大语言模型(LLM)上下文学习领域推出的系统性评测基准研究。该论文聚焦LLM在真实场景下"持续学习新知识、避免旧知识遗忘"的核心需求,解决了现有上下文学习评测体系碎片化、场景单一、缺乏LLM针对性的行业痛点,构建了覆盖多场景、多能力维度、标准化流程的CL-Bench基准,并基于主流开源LLM完成了大规模对比实验,为学术研究和工业落地提供了统一的评测框架与核心参考依据。
论文的核心目标可概括为三点:
构建首个面向LLM的系统性上下文学习评测基准,填补领域空白;
设计覆盖通用能力、指令遵循、长文本处理的多维评测体系,贴合LLM真实能力结构;
揭示现有上下文学习方法在LLM场景下的效果与局限,为后续研究指明方向。
二、LLM上下文学习的核心挑战与行业痛点
上下文学习(Context Learning, CL)是LLM从"静态模型"走向"动态演进"的关键能力——模型上线后需面对动态的业务需求:新增垂类知识(如医疗新指南)、拓展任务类型(如从问答到代码生成)、适配新应用域(如从英文到多语言),同时需避免对历史能力的"灾难性遗忘"(Catastrophic Forgetting)。
但截至论文发布前,行业面临三大核心痛点:
2.1 现有评测基准不适用于LLM
传统上下文学习研究主要针对:
小规模模型:参数量在百万级别(如ResNet、BERT-base)
简单任务:图像分类、文本分类等判别式任务
单一能力:仅评测特定任务的准确率
但LLM具有完全不同的特性:
参数量达数十亿至数千亿级别
任务类型极其多样(问答、推理、代码、对话、翻译等)
预训练阶段已积累海量通用知识,需要保护的"旧知识"范围更广
2.2 评测维度单一,忽略LLM核心能力
现有评测仅关注特定下游任务的性能,但LLM的价值在于其多维度的综合能力:
通用能力:数学推理、代码生成、知识问答、逻辑推理
指令遵循能力:准确理解并执行用户指令
长文本能力:处理长文档、长对话的能力
单一任务的评测结果无法反映上下文学习对LLM整体能力的影响。
2.3 缺乏标准化流程,可复现性差
不同研究采用的数据集、训练配置、评测方式不一致,导致:
不同上下文学习方法的对比结果缺乏参考性
学术研究成果难以复现和验证
工业落地缺乏可靠的选型依据
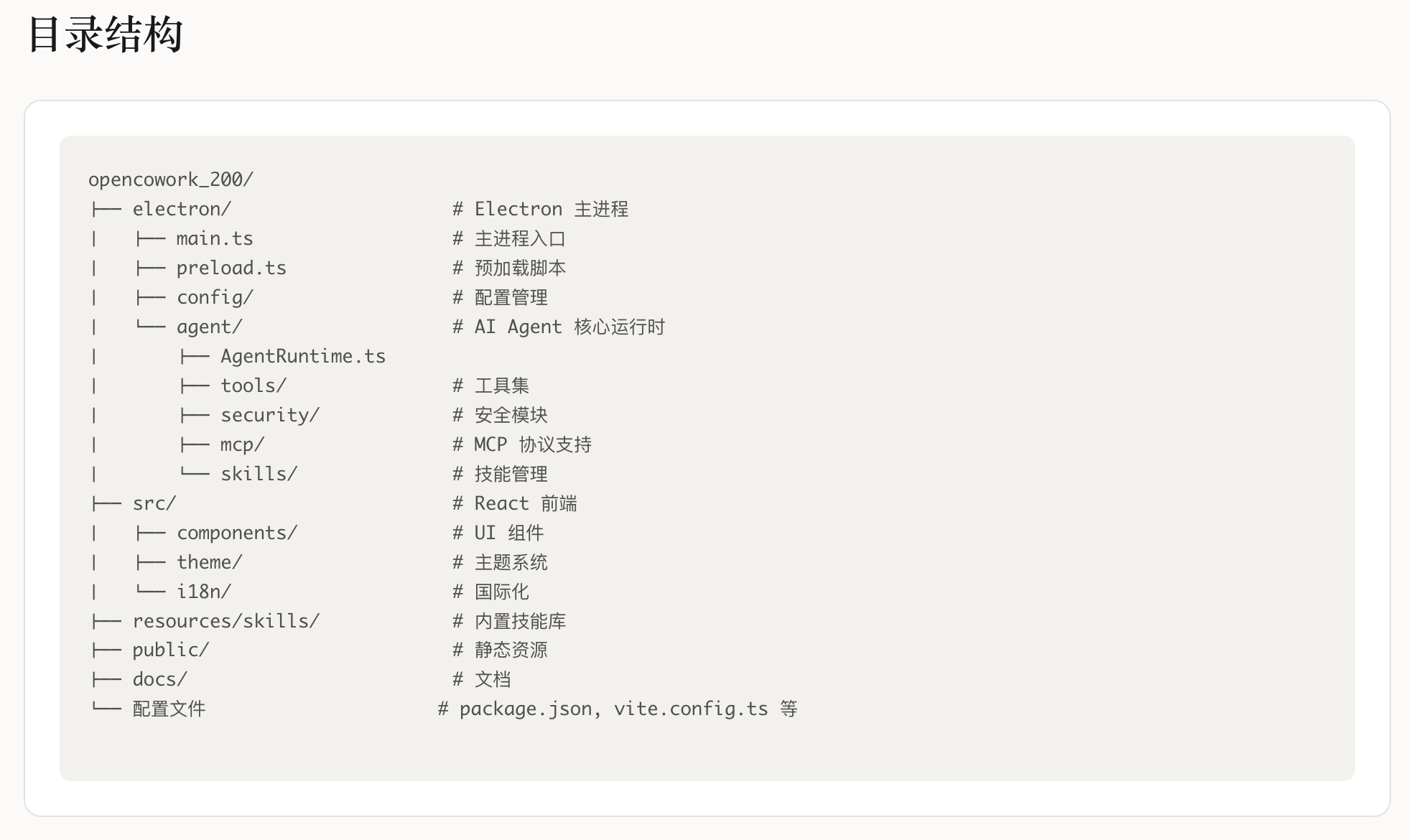
三、CL-Bench的核心设计与架构
CL-Bench以"系统性、多维度、可复现"为核心设计理念,构建了完整的评测框架。
3.1 三大能力评测维度
(1)通用能力(General Ability)
覆盖LLM最核心的基础能力,包含8个主流评测数据集:
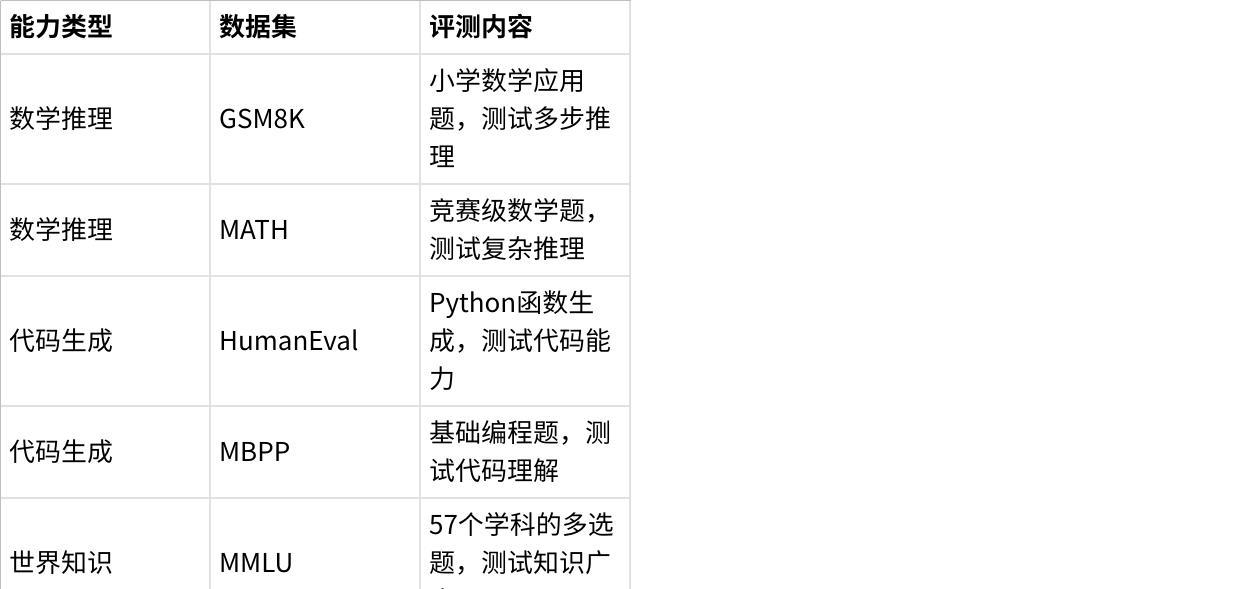
点击图片可查看完整电子表格
(2)指令遵循能力(Instruction Following)
使用IFEval数据集,评测模型对复杂指令的遵循程度:
格式约束遵循(如"用JSON格式回答")
内容约束遵循(如"回答不超过100字")
多重约束组合遵循
这是对话系统和Agent应用的核心能力。
(3)长文本处理能力(Long-Context Ability)
使用LongBench数据集,覆盖多种长文本任务:
长文档问答(Single/Multi-Doc QA)
长文本摘要(Summarization)
少样本学习(Few-shot Learning)
代码补全(Code Completion)
测试模型在4K-32K token长度下的性能表现。
3.2 两类持续学习场景
领域增量学习(Domain-Incremental Learning, DIL)
任务形式不变,领域知识递增
示例:模型依次学习医疗问答→法律问答→金融问答
挑战:新领域知识可能覆盖或干扰旧领域知识
任务增量学习(Task-Incremental Learning, TIL)
任务类型本身在变化
示例:模型依次学习文本分类→命名实体识别→关系抽取→问答生成
挑战:不同任务对模型参数的需求可能冲突
论文还设计了混合增量场景,同时包含领域和任务的变化,更贴近真实业务需求。
3.3 标准化评测指标体系
CL-Bench设计了完整的指标体系,量化上下文学习的各个维度:
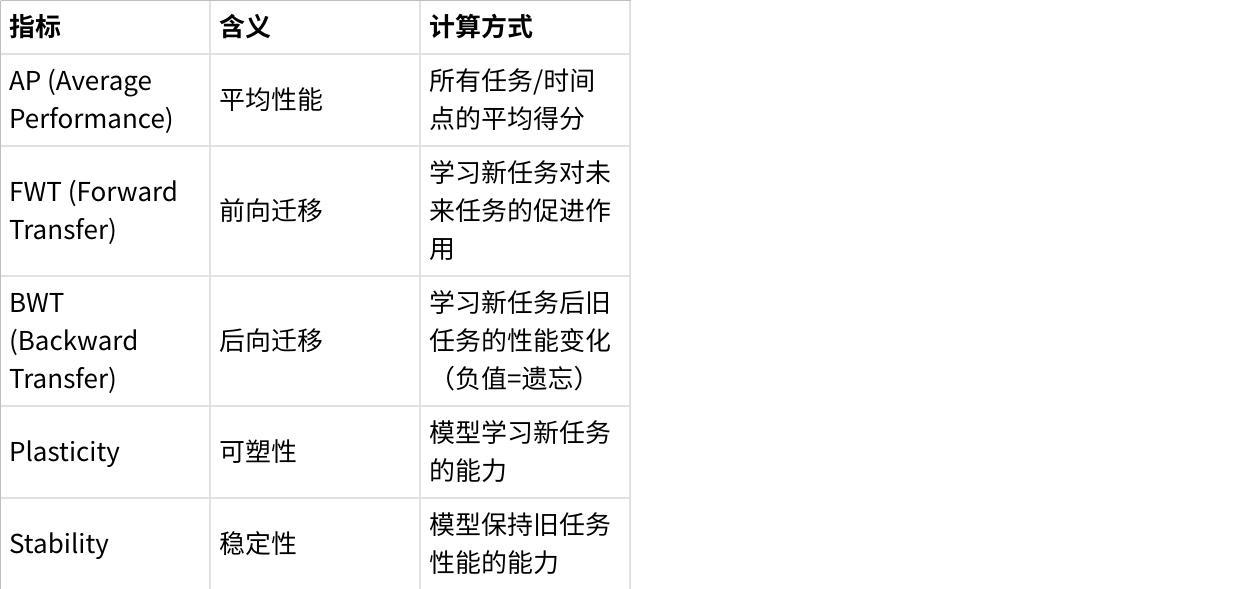
点击图片可查看完整电子表格
3.4 标准化实验流程
为确保可复现性,CL-Bench定义了统一的实验流程:
数据划分:固定的训练/验证/测试集划分,公开可复用
模型初始化:统一使用预训练checkpoint,不做额外预处理
训练配置:固定学习率(2e-5)、批次大小、训练轮次等超参数
评测时机:每学完一个任务后,评测所有已学任务+通用能力
指标计算:统一的计算逻辑和输出格式
四、大规模评测实验与结果分析
论文基于CL-Bench完成了系统性对比实验,覆盖多个主流LLM和持续学习方法。
4.1 测试的基座模型
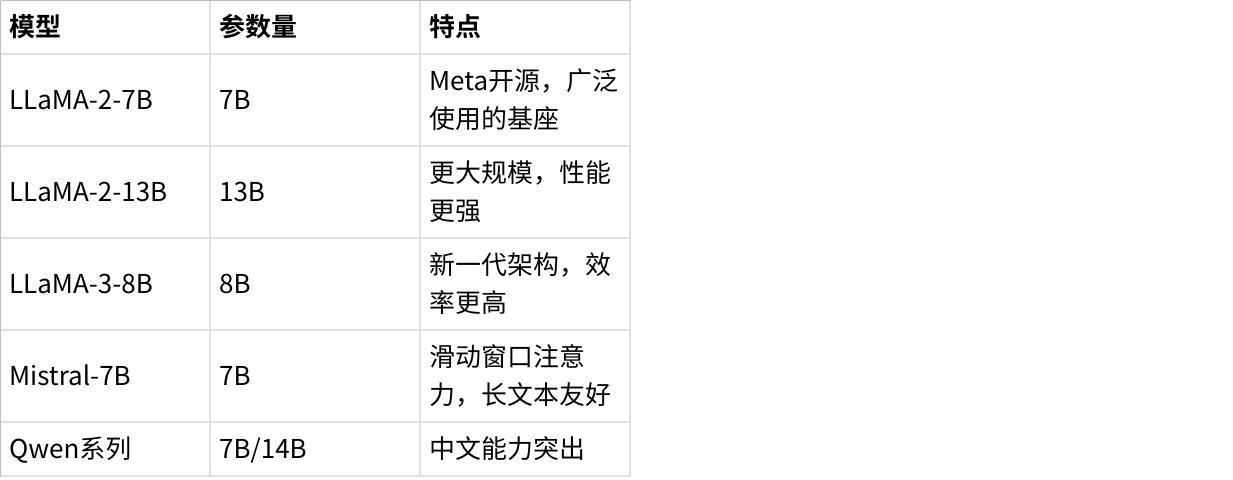
点击图片可查看完整电子表格
4.2 测试的上下文学习方法
正则化方法(Regularization-based)
EWC(Elastic Weight Consolidation):通过Fisher信息矩阵识别重要参数,对其变化施加惩罚
LwF(Learning without Forgetting):使用知识蒸馏,让新模型输出接近旧模型
L2正则化:简单限制参数变化幅度
重放方法(Replay-based)
Experience Replay:保存部分旧数据,学习新任务时混合训练
Generative Replay:用生成模型产生伪旧数据进行回放
架构方法(Architecture-based)
Progressive Networks:为新任务添加新模块,冻结旧模块
Adapter/LoRA:使用轻量级适配器,每个任务独立适配器
基线方法
Sequential Fine-tuning(Seq FT):直接顺序微调,无防遗忘措施
Multi-task Learning(MTL):所有数据混合训练(理论上界)
4.3 核心实验结果
结果1:灾难性遗忘在LLM中普遍存在
论文通过实验验证了在使用简单顺序微调(Sequential Fine-tuning)时,LLM会出现明显的灾难性遗忘现象。不同类型的能力在上下文学习过程中都会出现不同程度的性能下降,这证明了上下文学习研究在LLM领域的必要性和紧迫性。
结果2:现有上下文学习方法的比较
论文对多种上下文学习方法进行了评测,包括:
正则化方法(EWC、LwF、L2正则化):通过约束参数变化来减少遗忘
重放方法(Experience Replay):保存部分历史数据进行混合训练
架构方法(LoRA、Adapter):使用轻量级模块进行任务特定适配
论文展示了这些方法在不同场景下的表现,但具体的性能提升数值因任务、模型和配置而异。总体而言,不同方法各有优劣,需要根据具体应用场景(如是否允许存储历史数据、计算资源限制等)来选择合适的方法。
结果3:模型规模的影响
论文测试了不同规模的模型(如7B、13B等),发现模型规模对上下文学习性能有一定影响。一般来说,更大的模型在上下文学习中表现出更好的稳定性,但同时也带来更高的计算成本。
结果4:不同能力的遗忘规律
论文发现了一个重要规律——不同能力的遗忘速度存在差异:
某些能力(如数学推理、代码生成、长文本处理)在持续学习过程中表现出较高的敏感度,更容易受到新任务训练的影响;而一些基础能力(如基本语言理解、简单知识问答)则相对更加稳定。这一发现对于设计针对性的保护策略具有重要意义。
结果5:任务顺序的影响
论文测试了不同的任务学习顺序,发现任务顺序对最终性能有显著影响。合理的任务安排可以提升持续学习的效果,而不当的顺序可能加剧遗忘问题。
结果6:长文本能力的特殊脆弱性
长文本能力表现出独特的脆弱性:
即使只学习短文本任务,长文本能力也会下降
恢复长文本能力需要专门的长文本数据重新训练
原因推测:位置编码和长距离注意力模式被短文本训练破坏
五、论文核心发现与行业洞察
基于CL-Bench的大规模实验,论文得出了一系列具有指导意义的结论:
5.1 方法层面
不存在"全场景最优"的上下文学习方法:需根据具体场景选择
不同方法各有优劣:重放方法、正则化方法、适配器方法在不同场景下表现不同,需要权衡性能、隐私、存储成本等多个因素
5.2 模型层面
模型规模对上下文学习有影响:不同规模的模型在上下文学习中表现出不同的特性
预训练质量很重要:预训练阶段的数据质量和多样性会影响上下文学习的效果
不同能力需要差异化保护策略:某些能力(如数学、代码、长文本)可能需要特别关注
5.3 训练层面
增量步长的影响:论文探讨了不同增量学习步长对性能的影响
任务顺序设计至关重要:合理的任务安排可以改善上下文学习效果
混合训练策略:结合新旧数据的训练策略是一种实用的方法
5.4 评测层面
单一指标会严重误导决策:需同时关注性能、遗忘率、计算成本
通用能力评测不可或缺:仅看下游任务会遗漏关键能力退化
长期评测很重要:短期实验可能低估遗忘的累积效应
六、行业意义与未来研究方向
6.1 CL-Bench的行业价值
学术层面:
填补了LLM上下文学习统一评测基准的空白
为上下文学习算法创新提供了可复现的验证框架
揭示了LLM上下文学习的独特规律,指明研究方向
工业层面:
明确了LLM上下文学习落地的核心考量维度
为企业选型、算法优化提供了量化参考
提供了标准化的评测工具链
生态层面:
开源的代码和数据降低了研究门槛
统一的评测标准促进了学术交流
为后续研究提供了可扩展的基础设施
6.2 未来核心研究方向
参数高效微调与上下文学习的深度结合:LoRA、Adapter等方法的模块化特性天然适合上下文学习,值得深入探索
智能数据选择与重放:不是所有旧数据都同等重要,如何选择最具代表性的数据进行重放是关键问题
能力解耦与保护:能否将不同能力映射到不同参数子集,实现选择性保护?
长文本能力的专项保护:针对长文本能力的特殊脆弱性,需要专门的保护机制
自适应上下文学习策略:根据任务特性自动选择最优的上下文学习方法和超参数
长周期上下文学习评测:当前实验主要覆盖5-10轮增量,需要拓展到50+轮的长周期评测
6.3 落地建议
对于企业而言,基于CL-Bench的结论可优化LLM上下文学习落地策略:
模型选择:根据具体需求和资源情况选择合适规模的模型
方法选择:根据应用场景的具体约束(隐私要求、存储限制、计算资源等)选择合适的上下文学习方法
训练策略:合理设计任务学习顺序,考虑增量学习的步长
评测策略:建立多维度的评测体系,不仅关注下游任务性能,也要监控通用能力的变化
监控机制:建立持续的能力监控,及时发现和修复能力退化
七、总结
CL-Bench这篇论文的核心贡献可以概括为:
首次系统性地定义了LLM上下文学习的评测框架,覆盖通用能力、指令遵循、长文本处理三大维度
全面测试了7类主流上下文学习方法,揭示了它们在LLM上的效果与局限
发现了LLM上下文学习的独特规律:不同能力的差异化遗忘、任务顺序的重要性、长文本能力的特殊脆弱性
为后续研究和工业落地提供了基础设施,包括开源代码、标准化流程、可扩展框架
这篇论文的价值在于它的"基础设施"属性——它不是提出一个新的上下文学习方法,而是建立了一套评测标准和实验框架,让后续的研究者有据可依,让工业落地有章可循。对于关注大模型长期演进的研究者和工程师来说,这是一篇必读的基础性工作。
]]>