Dataset design that reflects benchmark intent, not just task accumulation
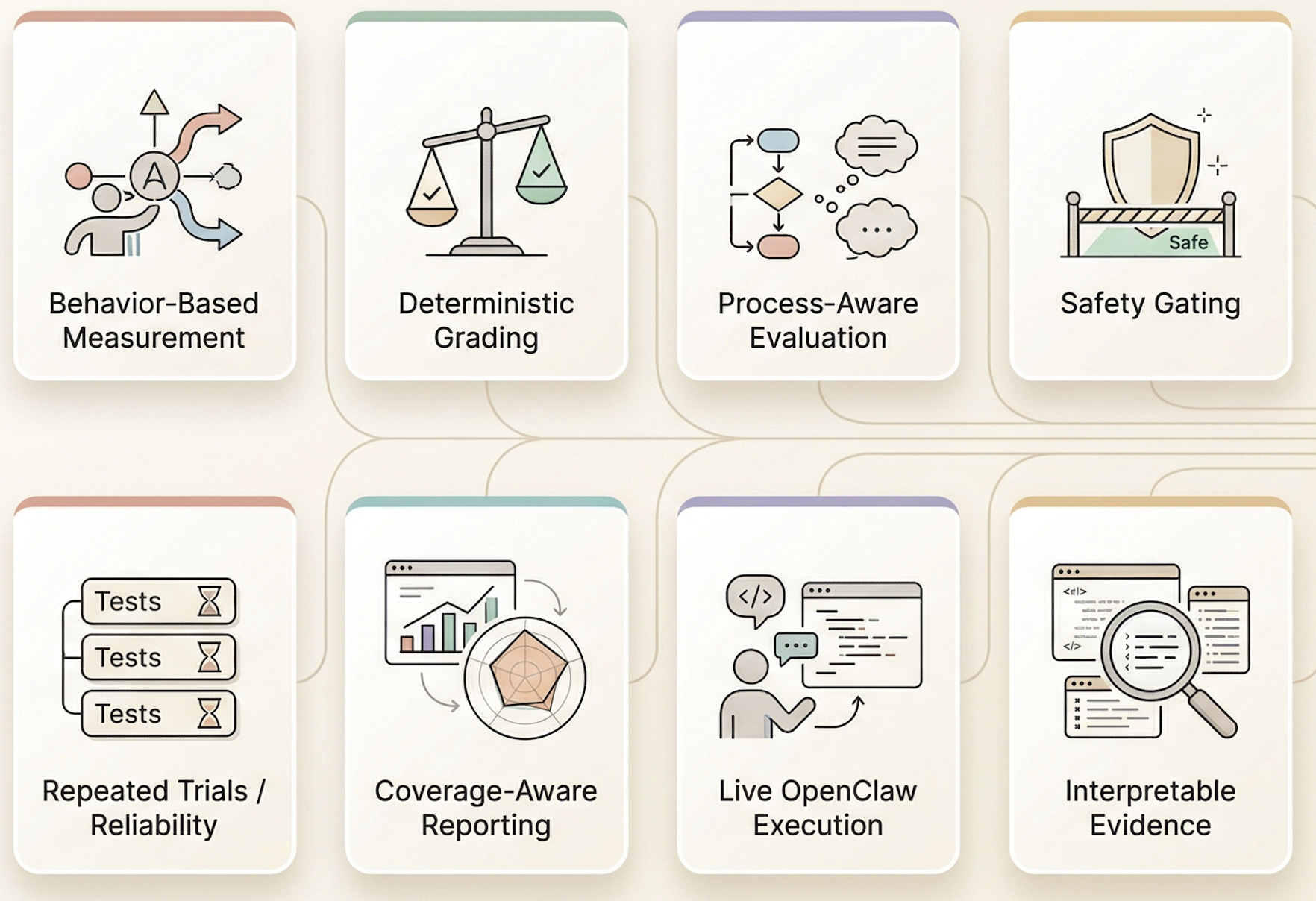
A benchmark becomes more useful when its task set is legible. OpenClawBench treats benchmark membership as first-class metadata, keeps difficulty explicit, and exposes multiple official slices so users can inspect both count and influence instead of staring at one opaque total.
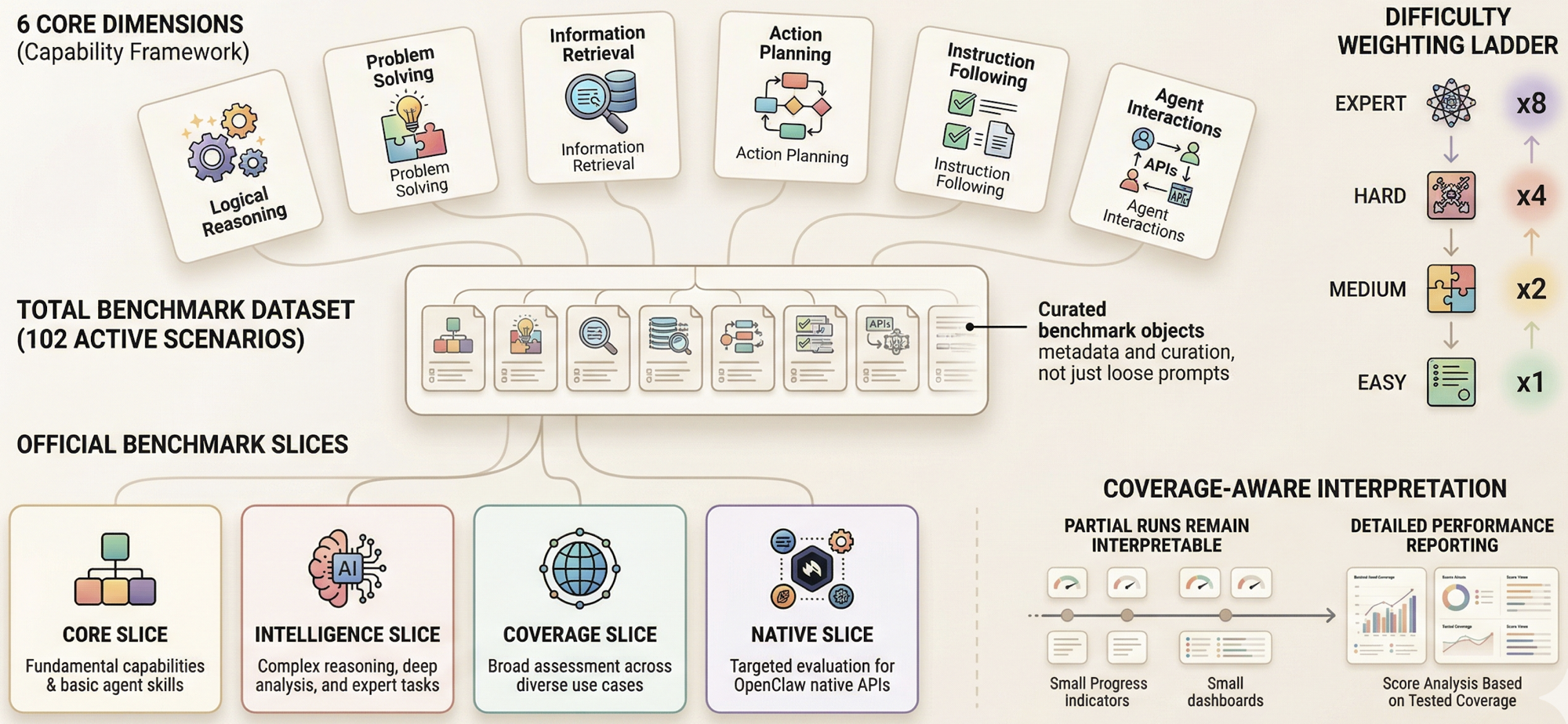
Difficulty weighting
Harder tasks matter more
Difficulty weights are explicit: easy, medium, hard, and expert scale as 1 / 2 / 4 / 8. This prevents the benchmark from being dominated by easy wins and lets more demanding scenarios carry proportionally more influence.
Benchmark slices
Different questions deserve different views
core asks who is strongest on the main ranking path. intelligence asks about broader capability. coverage tracks regression breadth. native makes OpenClaw-native surfaces visible without forcing them to dominate the main leaderboard prematurely.
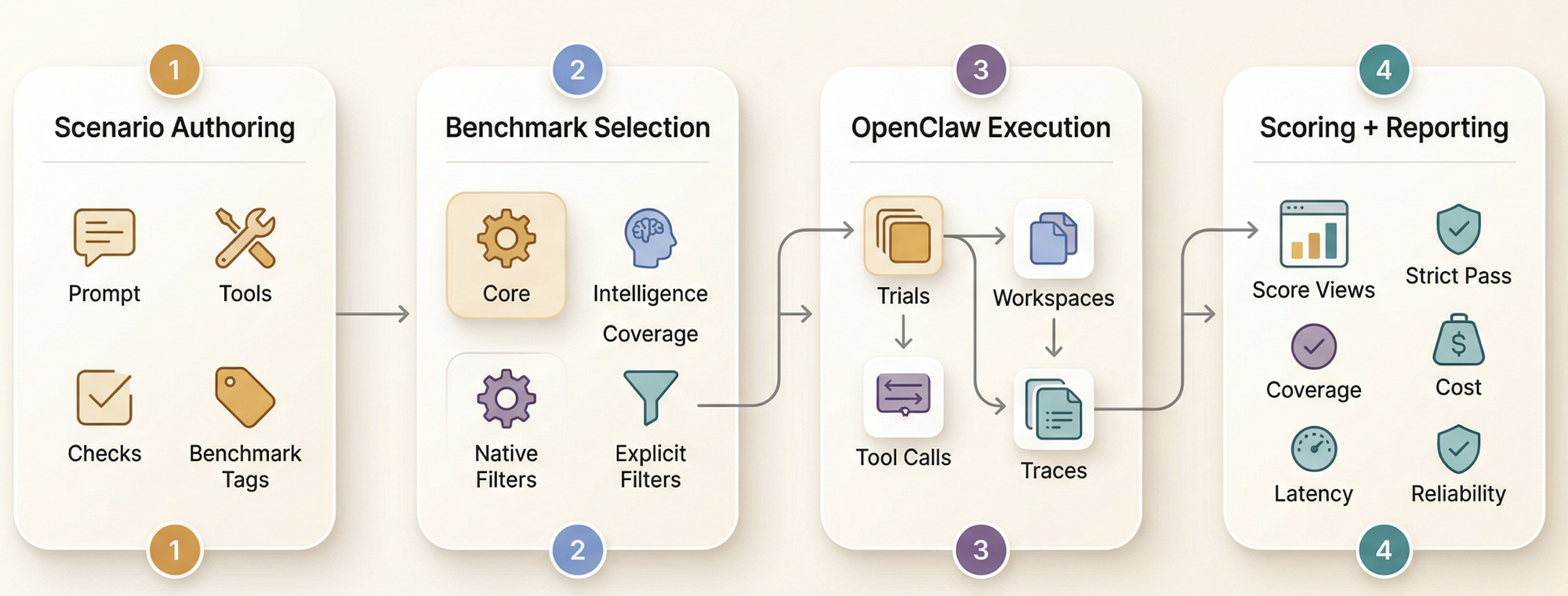
Scenario metadata
Tasks are benchmark objects, not loose prompts
Each scenario can declare tools, checks, tags, execution mode, difficulty, pass threshold, workspace material, and custom grading logic. That makes the dataset easier to extend without weakening benchmark semantics.
Live evidence
Per-trial workspaces keep runs observable
The runner creates controlled workspaces and the reporting layer records cost, latency, token usage, and execution metadata. This keeps the dataset tied to observable agent behavior rather than to abstract answer-only evaluation.
Coverage transparency
Partial runs remain interpretable
Reports expose coverage, covered weight, normalized capability, and normalized score on covered slices. That matters because serious benchmarking should show how much evidence exists, not just a headline number.
Extensibility
New tasks can grow without rewriting the harness
Most benchmark growth happens declaratively through scenario YAML and optional custom checks. This keeps the benchmark flexible while preserving a clear boundary between content, execution, scoring, and reporting.