关于Agent评估,我的一些思考
写在前面,2025年被称为”AI Agent之年”。当越来越多的Agent从实验室走向生产环境,如何科学地评估它们的能力,成了一个绑不开的话题。
但说实话,Agent评估比想象中要难得多。我花了不少时间研究这个领域,读了一些论文,也看了一些工具,逐渐形成了自己的一些想法。写下来,算是一个阶段性的梳理。
一、为什么Agent评估和传统LLM评估不一样?
这个问题我思考了很久。最核心的区别在于:传统LLM评估像考试答题,Agent评估像项目实战。

点击图片可查看完整电子表格
举个例子:让LLM回答”北京的首都是哪里”(虽然问题本身有点奇怪),答案就一个。但让Agent”帮我订一张下周去北京的机票”,正确答案可以有无数个——不同航班、不同价格、不同时间,都可能是”对的”。
更麻烦的是,两个Agent都成功订到了票,但一个5分钟搞定,另一个折腾了半小时、尝试了十几次才成功。这两个能等同吗?显然不能。过程的质量,有时候比结果更重要。
二、我理解的评估框架:三层金字塔
在看了不少资料后,我觉得Agent评估可以用一个”三层金字塔”来理解:
┌─────────────────────────────────────────┐
│ 第三层:生产就绪度 (10-15%) │
│ 成本、延迟、安全、稳定性 │
├─────────────────────────────────────────┤
│ 第二层:应用效果 (25-30%) │
│ 任务完成、输出质量、用户满意度 │
├─────────────────────────────────────────┤
│ 第一层:核心能力 (60%) │
│ 规划、工具使用、推理、记忆 │
└─────────────────────────────────────────┘
底层是核心能力,占比最大。一个Agent如果连基本的规划、推理、工具使用都做不好,其他都是空谈。
中间层是应用效果,考察的是”这个Agent在实际任务中表现如何”。
顶层是生产就绪度,关心的是”这个Agent能不能上线”——成本可控吗?响应够快吗?安全吗?
这个框架帮我理清了评估的优先级:先确保核心能力过关,再看应用效果,最后考虑生产化。
三、核心能力评估:从哪些维度切入?
3.1 规划与推理能力
这是Agent最核心的能力。一个好的Agent应该能把复杂任务分解成合理的步骤,并逐步执行。
我觉得有一个指标特别有价值:Progress Rate(进度率),来自ICLR 2024的AgentBoard论文。它的计算方式是:
Progress Rate = 实际完成的有效步骤数 / 理想路径的总步骤数
这个指标的好处是:
不是二元判断:不再是简单的”成功/失败”,而是一个连续的进度度量
能定位问题:可以知道Agent”卡在哪一步”
支持部分成功:完成了80%和完成了20%,应该有区别
比如一个电商购物任务,理想路径是:搜索→筛选→比价→加购物车→结算。如果Agent完成了前四步但结算失败,Progress Rate是0.8,比完全失败好太多。
3.2 工具使用能力
Agent的强大之处在于能调用各种工具。但工具使用的评估也分层次:
L1: 单工具调用 — 能正确理解工具描述,传递正确参数
L2: 多工具顺序调用 — 理解工具间的依赖关系
L3: 并行与嵌套调用 — 识别可并行的操作
L4: 动态工具发现 — 在未知环境中探索和学习新工具
有一个有趣的研究发现让我印象深刻:在Web任务中,纯API方式的成功率(32.1%)远高于纯浏览器方式(14.9%),而混合方法效果最好(38.9%)。
这说明什么?工具选择本身就是一种能力。如果Agent明明可以用API却选择了笨拙的浏览器自动化,即使最后成功了,也说明它的”工具智商”有待提高。
3.3 记忆管理能力
这是一个容易被忽视的维度。Agent需要在长对话中记住关键信息,同时过滤掉不重要的内容。
我把记忆能力分为四个方面:
准确检索:能从历史中提取正确信息
在线学习:能在对话中学习新知识
长程理解:跨多轮交互维持上下文一致性
选择遗忘:能丢弃过时或不相关的信息
最后一点特别重要。一个好的Agent不是记住所有东西,而是记住该记住的,忘掉该忘掉的。这和人类的记忆机制很像。
3.4 自我反思与改进能力
这个能力评估的是:Agent犯错后,能否从反馈中学习并改进?
有一个指标叫Reflection Score:
Reflection Score = (二次成功率 - 初次成功率) / (1 - 初次成功率)
比如初次成功率30%,给反馈后二次成功率提升到75%,那Reflection Score = (0.75-0.30)/(1-0.30) = 0.64。意味着Agent实现了64%的潜在改进空间。
这个指标反映的是Agent的”可教性”——一个能从错误中学习的Agent,比一个僵化的Agent更有价值。
四、应用效果评估:超越简单的成功率
4.1 多级成功率
单纯的”成功/失败”太粗糙了。我更倾向于用多级评估:
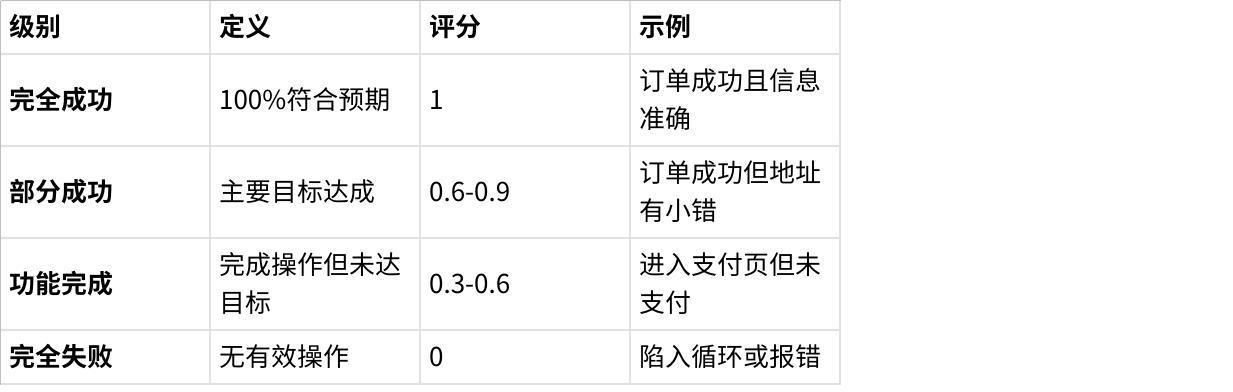
点击图片可查看完整电子表格
4.2 LLM-as-a-Judge
用更强大的LLM来评估Agent输出,是2025年的主流做法。它的好处是:
成本比人工评估低得多
一致性比人工评估高
可以处理开放式任务(没有标准答案的场景)
但也有局限:Judge LLM自己也可能犯错。所以我的建议是抽样验证——定期抽取一部分案例做人工复核,确保Judge LLM的判断是靠谱的。
4.3 用户满意度模拟
在开发阶段,真实用户反馈往往拿不到。一个替代方案是用LLM模拟用户打分:
作为用户,你的问题是:{query}
Agent回复:{response}
请评分(1-5):
5 - 非常满意,完美解决
4 - 满意,基本解决
3 - 一般,有些帮助
2 - 不满意,没解决
1 - 非常不满意
只输出分数。
这种方法当然不完美,但比没有用户视角要好。
五、生产就绪度:不能忽视的现实问题
5.1 成本效率
这是很多人忽视的维度。一个Agent跑一次任务花多少钱?
有一个研究数据让我印象深刻:在科学数据分析任务中,通用模型GPT-4每任务成本$1.84,成功率32.4%;而专用Agent每任务成本$0.92,成功率41.2%。成本降了一半,效果还更好。
所以评估不能只看效果,还要看成本-效果比。
5.2 延迟与性能
几个关键指标:
TTFT (Time To First Token):首个token返回时间,目标<500ms
端到端延迟:完整任务时间,交互式场景目标<10s
步骤延迟:单步操作时间,目标<2s/步
延迟问题往往藏在细节里。我见过的案例:某个Agent总体延迟很高,分析发现是某个搜索步骤占了60%的时间,优化这一个点就能大幅提升。
5.3 安全性
这是Agent评估中最敏感的维度。核心关注三点:
操作安全:不执行有害操作(比如误删文件)
隐私保护:不泄露敏感信息
拒绝能力:能识别并拒绝不当请求
一个好的Agent应该在”有用”和”安全”之间找到平衡——太保守了会频繁误拒正常请求,太激进了又有安全风险。
六、评估范式的转变:2025年的新趋势
6.1 从静态到动态
传统做法是准备一套固定的测试集,跑一遍得个分数。但问题是:模型可能”记住”了测试集,分数虚高。
新趋势是动态基准(Live Benchmarks):
实时环境,持续更新
自动生成新测试用例
防止”刷榜”
比如τ-Bench就是一个典型,它模拟真实的用户交互和工具调用,环境是动态变化的。
6.2 从结果到过程
以前只关心”任务成没成”,现在更关心”怎么完成的”。这要求我们:
追踪完整的执行轨迹
分析每一步的决策是否合理
诊断失败原因(是规划问题?工具问题?还是推理问题?)
6.3 从单一到多维
一个准确率数字说明不了什么。现在的趋势是多维度平衡:
成本 vs 质量
速度 vs 准确性
能力 vs 安全
这要求我们建立多指标体系,而不是追求单一分数。
七、成本控制:分层评估策略
大规模评估的成本问题困扰很多团队。一个实用的策略是分层评估:
L1层 - 规则评估(覆盖~80%)
成本:$0
方法:简单规则快速筛选明显正确或错误的案例
例如:输出非空、包含关键词、格式正确
L2层 - 小模型Judge(覆盖~15%)
成本:约$0.001/案例
方法:用GPT-3.5等小模型评估L1失败的案例
L3层 - 大模型+人工(覆盖~5%)
成本:约$0.05/案例
方法:对L2仍不确定的案例,用GPT-5深度评估并人工复核
通过分层,1000个案例的评估成本能从纯人工的$5000降到$20左右。
八、一些悬而未决的问题
写到最后,还是要承认有些问题我没想清楚:
评分权重如何确定?
不同检查点的重要性显然不同,但权重该怎么定?目前没有科学的方法,更多靠经验和业务判断。
如何处理Agent的非确定性?
同样的输入,Agent可能给出不同的输出。跑多少次取平均?怎么报告置信区间?这些实操细节需要更多探索。
基准测试和实际表现不符怎么办?
见过不少案例:Agent在基准测试上分数很高,实际用起来却不行。可能是数据泄露、分布偏移,也可能是指标选得不对。这个gap怎么缩小?
多Agent协作怎么评估?
单个Agent评估已经很难了,多个Agent协作更复杂。怎么评估协作效率?怎么处理Agent间的冲突?这是个新兴领域,方法论还在探索中。
九、写在最后
Agent评估是一个快速演进的领域。我在这篇文章里分享的,是截至目前我的理解,肯定不完美,可能很快就会过时。
但有一点我比较确定:评估的目的不是为了打分,而是为了理解Agent的能力边界,指导改进方向。
一个好的评估体系应该:
能发现问题:告诉我们Agent哪里做得不好
能解释原因:不只是”失败了”,而是”为什么失败”
能指导优化:提供改进的方向
成本可控:不能比开发Agent本身还贵
如果你的评估体系能做到这几点,那就是一个有用的体系,不管它有多”土”。
最后,推荐几个我觉得不错的资源:
学术论文:
Survey on Evaluation of LLM-based Agents (2025)
AgentBoard (ICLR 2024) - Progress Rate的出处
WebArena - Web Agent基准测试
开源工具:
DeepEval: https://github.com/confident-ai/deepeval
AgentBoard: https://github.com/hkust-nlp/agentboard
LangSmith: https://www.langchain.com/langsmith
写于2025年12月